Multi Lingual Audio Transalation using LLMS
Objective
The objective of this project is to develop a multilingual audio translation system that effectively translates spoken English into either Hindi or Telugu using advanced Large Language Models (LLMs). The system aims to leverage the fine-tuned models, such as Gemma2, Qwen-7B, and Mistral-7B, trained on the IITB English-Hindi and Bharat Telugu datasets. The main goal is to provide real-time translations that maintain both accuracy and contextual relevance across various use cases, such as education, business, and cross-cultural interactions. By integrating automatic speech recognition (ASR) for converting speech to text and the fine-tuned LLMs for translation, this project will break language barriers and enable seamless communication in multi-lingual environments.
Abstract
The paper proposes a multilingual audio translation system that utilizes Large Language Models (LLMs) to convert spoken English into Hindi or Telugu. The system leverages three advanced models—Gemma2, Qwen-7B, and Mistral-7B—fine-tuned using the IITB English-Hindi dataset and the Bharat Telugu dataset, both available on Hugging Face. These datasets are essential for training the models to perform high-quality translations across these languages, ensuring both accuracy and contextual relevance. The system works by first converting spoken English into text using automatic speech recognition (ASR), followed by translation into either Hindi or Telugu, depending on the user's choice. The LLMs used in this project are based on transformer architectures, known for their ability to capture long-range dependencies and contextual relationships within sequences. The project demonstrates how fine-tuning pre-trained models on domain-specific datasets can enhance the translation of complex linguistic structures, allowing the system to provide real-time translations with high fidelity. The proposed system offers significant potential for breaking language barriers in communication, with applications in areas such as education, business, and cross-cultural interactions, particularly in regions where Hindi and Telugu are widely spoken.
Keywords: multilingual translation, audio translation, Gemma2, Qwen-7B, Mistral-7B, IITB English-Hindi dataset, Bharat dataset, Hugging Face, speech-to-text, fine-tuning, language models, real-time translation.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
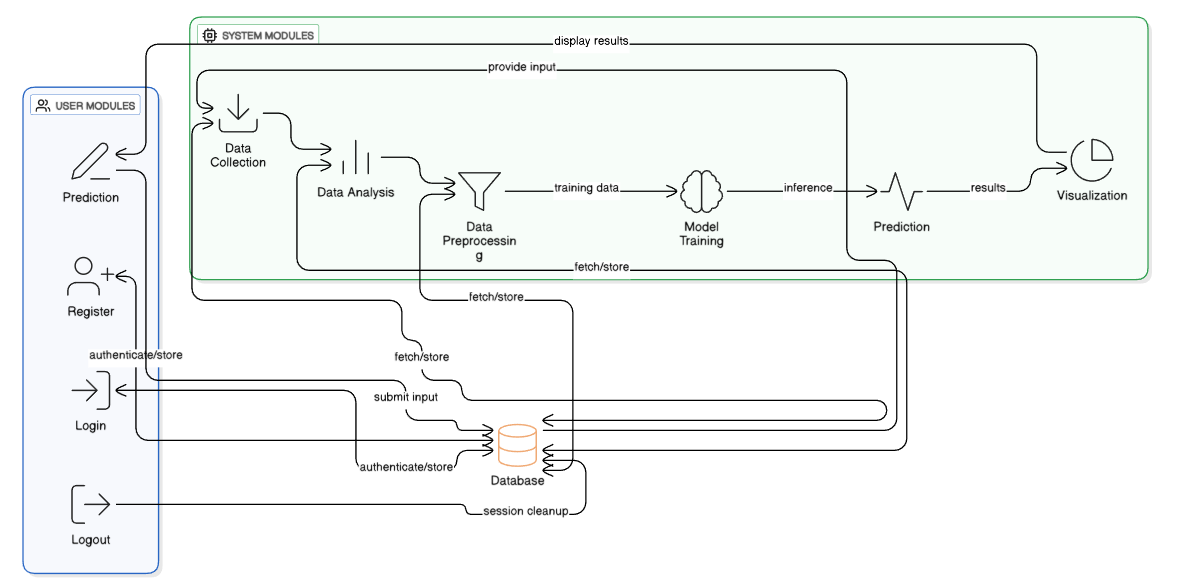
Block Diagram
Specifications
SOFTWARE REQUIREMENS
Operating System : Windows 7/8/10
Server side Script : html,css,js
Programming Language : Python
Libraries : Django, Pandas, Torch, Keras, Sklearn, Numpy , Seaborn
IDE/Workbench : VSCode
Server Deployment : Xampp Server
Database : SQLite
HARDWARE REQUIREMENTS
Processor - I3/Intel Processor
RAM - 8GB (min)
Hard Disk - 128 GB
Key Board - Standard Windows Keyboard
Mouse - Two or Three Button Mouse
Monitor - Any

Demo Video


Request for Video
Related Projects
 Paper Publishing
Paper PublishingRequest Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.