Machine Learning for Adaptive RealTime Fraud Detection in Financial Systems.
Objective
The objective of this project is to design an integrated machine learning framework that performs multi-class fraud detection and binary credit risk classification using synthetic financial data, addresses class imbalance with resampling, compares ensemble models, enhances transparency through explainable AI, and delivers predictions via a modular, web-based application platform architecture.
Abstract
Fraud identification and credit risk evaluation are essential components of financial data analysis systems. This project introduces a machine learning–based framework designed to detect multiple fraud categories and classify credit risk using a synthetic dataset. The proposed system performs multi-class classification to identify phishing, card fraud, payment fraud, lottery fraud, and non-fraud cases, while also conducting binary classification to determine low-risk and high-risk credit profiles. To improve predictive performance and model stability, ensemble learning algorithms such as Random Forest, XGBoost, and LightGBM are implemented and compared. Class imbalance within the dataset is addressed using the Synthetic Minority Over-sampling Technique, which enhances minority class representation during training. In addition to accuracy, the project emphasizes model interpretability through explainable AI techniques that provide insight into feature contributions influencing predictions. The system is deployed through a Flask-based backend integrated with a web interface that allows users to upload datasets, explore data distributions, and obtain prediction results. The modular design supports clear separation between data processing, model execution, and user interaction. This project demonstrates a comprehensive analytical workflow that combines data preprocessing, advanced classification models, and interpretability to support research-focused evaluation of fraud patterns and credit risk behavior using structured synthetic data.
Keywords: Fraud Detection, Credit Risk Classification, Machine Learning, Ensemble Models, SMOTE, Explainable AI, Synthetic Dataset, Flask Framework, Multiclass Analysis, Risk Prediction.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
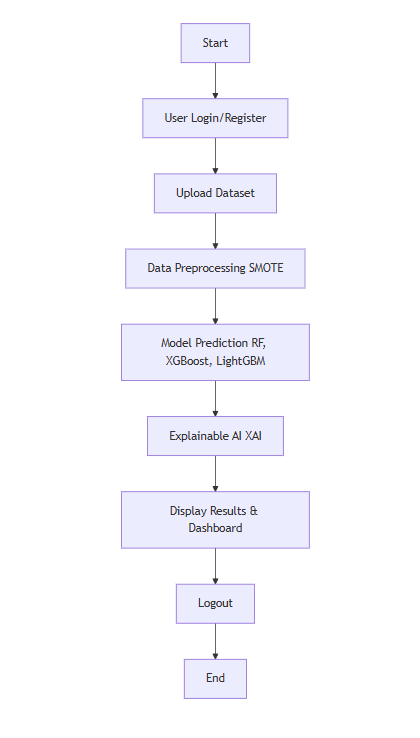
Block Diagram
Specifications
3.3 Hardware Requirements
Processor - I3/Intel Processor
Hard Disk - 160GB
Key Board - Standard Windows Keyboard
Mouse - Two or Three Button Mouse
Monitor - SVGA
RAM - 8GB
3.4 Software Requirements
Operating System : Windows 7/8/10
Programming Language : Python
Libraries : Pandas, Numpy, scikit-learn.
IDE/Workbench : Visual Studio Code.
Framework : Flask




Related Projects
 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.