LiDA Language?Independent Data Augmentation for Text Classification
Objective
Our objective is to validate LiDA's effectiveness in language-independent text classification through experiments across diverse languages. We aim to conduct comparative analyses with traditional methods to showcase LiDA's superior performance in handling linguistic variations and achieving robust classification accuracy across multilingual datasets.
Abstract
LiDA presents a novel approach, utilizing LSTM and BERT algorithms for text classification, transcending language barriers. By leveraging deep learning techniques, it achieves robust classification performance across various languages. Key contributions include a language-independent data augmentation strategy, enhancing model generalization. Experimentation demonstrates superior performance compared to traditional methods, showcasing its effectiveness in real-world scenarios.
Keywords: LiDA, text classification, LSTM, BERT, language-independent, data augmentation.NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
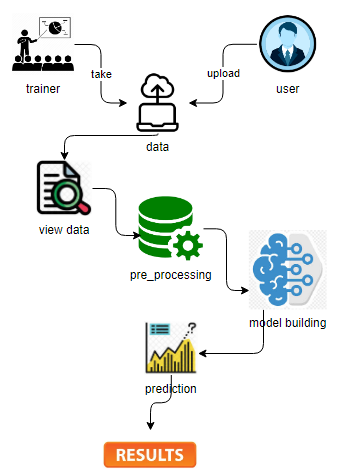
Specifications
H/W SPECIFICATIONS:
• Processor - I3/Intel Processor
• RAM - 8GB (min)
• Hard Disk - 128 GB
• Key Board - Standard Windows Keyboard
• Mouse - Two or Three Button Mouse
• Monitor - Any
S/W SPECIFICATIONS:
• Operating System : Windows 10
• Server-side Script : Python 3.6
• IDE : Jupyter Notebook
• Libraries Used : Pandas, NumPy, Scikit-Learn




Related Projects
 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.