A Web Application for Speech to Text Classification
Objective
The main objective of the project is to do an application for converting speech to text using deep learning techniques.
Abstract
This document is a guide to the basics of using Speech-to-Text. This conceptual guide covers the types of requests you can make to Speech-to-Text, how to construct those requests, and how to handle their responses. We recommend that all users of Speech-to-Text read this guide and one of the associated tutorials before diving into the API itself. A Speech-to-Text API synchronous recognition request is the simplest method for performing recognition on speech audio data. Speech-to-Text can process up to 1 minute of speech audio data sent in a synchronous request. After Speech-to-Text processes and recognizes all of the audio, it returns a response.
A synchronous request is blocking, meaning that Speech-to-Text must return a response before processing the next request. Speech-to-Text typically processes audio faster than realtime, processing 30 seconds of audio in 15 seconds on average. In cases of poor audio quality, your recognition request can take significantly longer.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
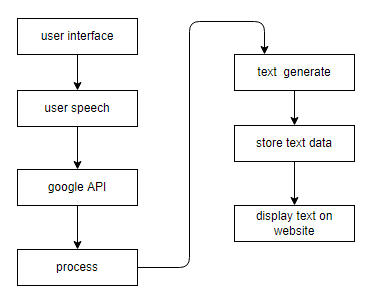
Specifications
H/W Specifications:
- Processor : I5/Intel Processor
- RAM : 8GB (min)
- Hard Disk : 128 GB
S/W Specifications:
- Operating System : Windows 10
- Technology : Python 3.6+
- IDE : PyCharm,
- Data base : MySql
- Front end : HTML, CSS, JS
- Libraries Used : Numpy, IO, OS, Flask, pandas
Learning Outcomes
- What are the soil parameters?
- what is Ph value?
- Crud operations.
- How Internet Works.
- What type of technology versions are used.
- Use of HTML, CSS on UI Designs.
- Data Parsing Front-End to Back-End.
- Working Procedure.
- Introduction to basic technologies used for.
- How project works.
- Input and Output modules.
- Frame work use.
- Python modules.
- Project Development Skills:
- Problem analyzing skills.
- Problem solving skills.
- Creativity and imaginary skills.
- Programming skills.
- Deployment.
- Testing skills.
- Debugging skills.
- Project presentation skills.
- Thesis writing skills.



Related Projects
 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.