A Machine Learning Methodology for Diagnosing Chronic Kidney Disease
Objective
The main objective of this project is to develop a machine learning-based system for early detection of chronic kidney disease (CKD) using patient data. It applies multiple algorithms (logistic regression, random forest, support vector machine, k-nearest neighbor, Naive Bayes, and feed forward neural network) to improve diagnostic accuracy and support timely treatment.
Abstract
Chronic kidney disease (CKD) is a global health problem with high morbidity and mortalityrate, and it induces other diseases. Since there are no obvious symptoms during the early stages of CKD, patients often fail to notice the disease. Early detection of CKD enables patients to receive timely treatment to ameliorate the progression of this disease. Machine learning models can effectively aid clinicians achieve this goal due to their fast and accurate recognition performance. In this study, we propose a machine learning methodology for diagnosing CKD. The CKD data set was obtained from the University of California Irvine (UCI) machine learning repository, which has a large number of missing values. KNN imputation was used to fill in the missing values, which selects several complete samples with the most similar measurements to process the missing data for each incomplete sample. Missing values are usually seen in real-life medical situations because patients may miss some measurements for various reasons. After effectively filling out the incomplete data set, six machine learning algorithms (logistic regression, random forest, support vector machine, k-nearest neighbor, Naive Bayes classifier and feed forward neural network) were used to establish models. Among these machine learning models, random forest achieved the best accuracy. By analyzing the misjudgments generated by the established models, we proposed an integrated model that combines logistic regression and random forest by using perceptron, best accuracy hence, we speculated that this methodology could be applicable to more complicated clinical data for disease diagnosis.
Keywords: - Logistic Regression, Random Forest, Support Vector Machine, k-nearest neighbor, Naive Bayes classifier, Stacking Classifier, and feed forward neural network.NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
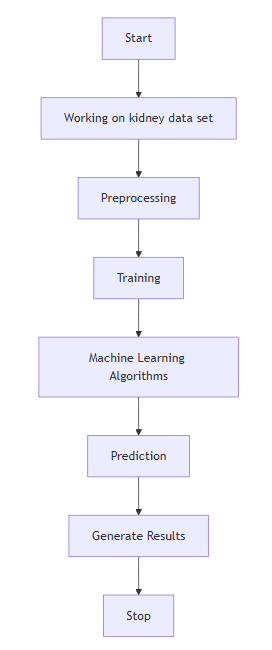
Specifications
H/W CONFIGURATION:
Processor - I3/Intel Processor
Hard Disk - 160GB
Key Board - Standard Windows Keyboard
Mouse - Two or Three Button Mouse
Monitor - SVGA
RAM - 8GB
S/W CONFIGURATION:
• Operating System : Windows 7/8/10
• Server side Script : HTML, CSS, Bootstrap & JS
• Programming Language : Python
• Libraries : Flask, Pandas, Mysql.connector, Os, Smtplib, Numpy
• IDE/Workbench : PyCharm
• Technology : Python 3.6+
• Server Deployment : Xampp Server




Related Projects
 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.