You Are What You Buy Personal Information Extraction From Anonymized Data.
Objective
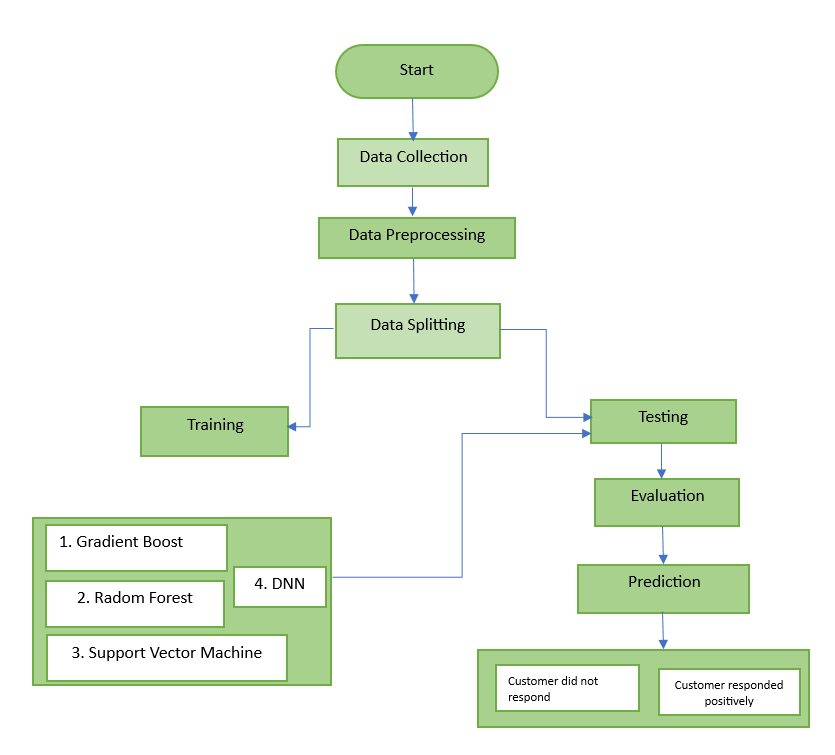
This project aims to analyze the relationship between consumer purchasing behavior and personal attributes (education, marital status, income) using anonymized data and machine learning models like Gradient Boosting, Random Forest, SVM, and DNN. The goal is to predict individual characteristics based on purchasing patterns to inform targeted marketing and enhance personalized consumer experiences while ensuring data privacy.
Abstract
This project explores the correlation between consumer purchasing behavior and personal attributes using anonymized data. By analyzing key variables such as education, marital status, income, and recent purchasing habits, we aim to uncover insights that define consumer profiles. We implement several machine learning models, including Gradient Boosting, Random Forest, Support Vector Machine (SVM), and Deep Neural Networks (DNN), to predict personal information based on purchasing data. The dataset encompasses various expenditures across food and luxury items, allowing for a comprehensive analysis of consumer preferences. Our findings will contribute to understanding how purchasing behavior reflects individual characteristics, ultimately offering valuable implications for targeted marketing strategies and personalized consumer experiences. Through this work, we highlight the potential of anonymized data in extracting meaningful consumer insights while ensuring privacy and data integrity.
Keywords: Gradient Boost, Random Forest, SVM and DNN, classification algorithms, Kaggle dataset.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
Specifications
H/W SPECIFICATIONS:
• Processor : I5/Intel Processor
• RAM : 8GB (min)
• Hard Disk : 128 GB
• Key Board : Standard Windows Keyboard
• Mouse : Two or Three Button Mouse
• Monitor : Any
S/W SPECIFICATIONS:
• Operating System : Windows 7+
• Server-side Script : Python 3.6+
• IDE : PyCharm.
• Libraries Used : Pandas, Numpy, Matplotlib, OS.




 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.