Two Stage Job Title Identification System for Online Job Advertisements
Objective
To develop an intelligent system that accurately classifies job titles and recommends contextually relevant roles using machine learning, deep learning, and semantic similarity techniques on job description data.
Abstract
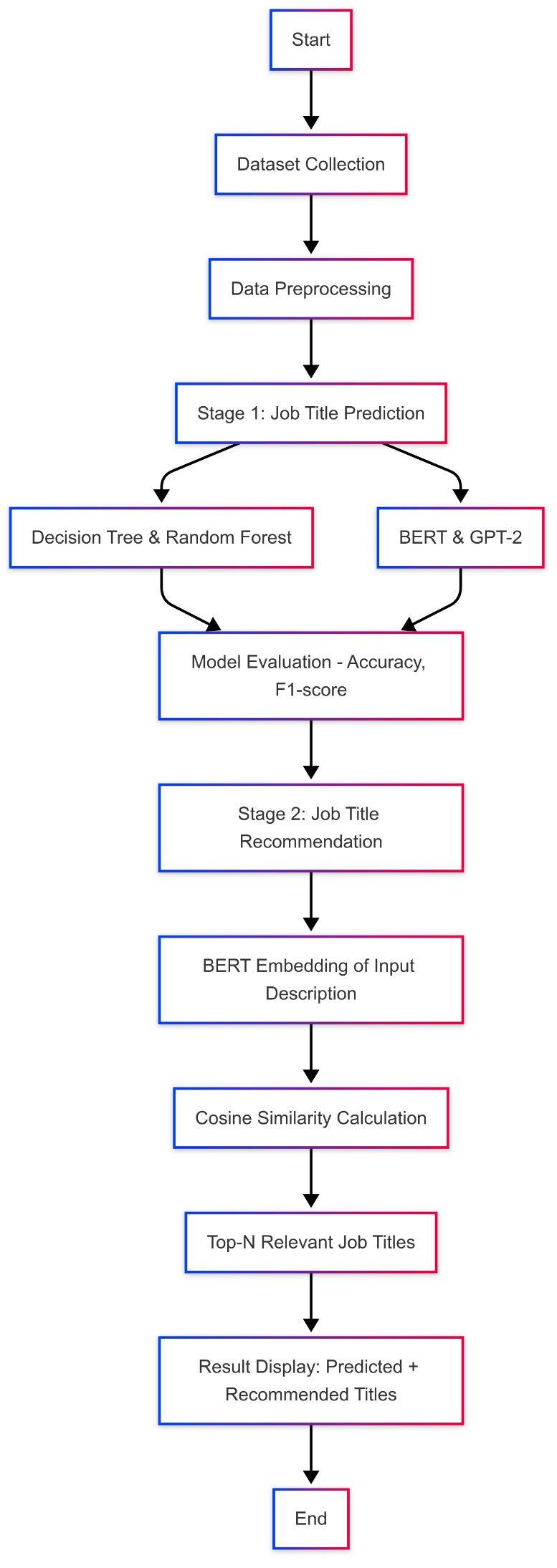
Contemporary recruitment systems generate numerous job descriptions disseminated through various online sources and job portals, thereby featuring a vast trove of unstructured textual data. Giving the correct job title to these job descriptions better candidate-job matching, better search relevance, and better user experience. However, differences in format, vocabulary, or style in job descriptions, while these traditional systems try to classify or recommend a job role, make the endeavor more difficult. Hence, we propose a Two-Stage Job Title Identification and Recommendation System employing machine learning, deep learning, and content-based recommendation approaches that perform and adapt better.
The first stage deals with job-title prediction. We combine traditional supervised learning models such as Decision Tree and Random Forest with advanced deep learning algorithms such as BERT (Bidirectional Encoder Representations from Transformer) and GPT-2. The training of these models is performed with a strong job dataset to infer titles from contextual and linguistic clues embedded in the job description. In contrast to the classical methods that provide transparency and are easy to interpret, BERT and GPT-2 bestow greater semantic understanding upon the text, enabling the model to generalize across industries and job formats.
The second step builds a Content-Based Recommendation System that recommends those job titles that have the highest contextual relevance with respect to the description as input. This is an implementation of semantic similarity techniques that rely on sentence embeddings (for instance, BERT embeddings) and cosine similarity measures. Unlike collaborative-filtering methods, this approach does not need the generation of any user-interaction information as it is suited to a cold start. This way, recommendations are tailored and relevant only by considering the given job description.
This is one of the most
important parts of our system: the usage of a high-quality and publicly
available dataset from Kaggle called "Job Descriptions Dataset”. The
dataset consists of two columns:
Job Title: The official job role.
Job Description: A detailed narrative outlining responsibilities,
qualifications, and expectations for the position.
With vacancies from important sites such as Glassdoor, Merojob.com, and Indeed,
the dataset covers various sectors and types of jobs, thus offering a very
diverse and equally representative sample of real-world postings. The dataset
is in CSV format under a CC0: Public-Domain License, thereby making it free for
Research and Educational purposes. The layout and contents thereafter make it
especially useful for NLP tasks such as classification, recommendation,
semantic analysis, or information retrieval.
If both interpretable machine learning and state-of-the-art deep learning models, together with a strong recommendation module and a real-world dataset, can be integrated into the proposed scheme, then classification can be made with higher accuracy and recommendations with contextual richness. This is a perfect solution for HRTech, job portals, selection automation, or talent analytics.
Keywords: Job Title Classification, Job Recommendation System, BERT, GPT-2, Decision Tree, Random Forest, NLP, Content-Based Filtering, Semantic Similarity, Job Description Analysis, Kaggle Dataset, Cosine Distance, Online Recruitment, Cold Start Problem, HR Automation
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram




 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.