Synthetic Speech Detection Through Short-Term and Long-Term Prediction Traces
Objective
The objective of our project is to develop a robust system for detecting synthetic speech by analyzing short-term and long-term prediction traces. We aim to achieve this by exploring advanced deep learning algorithms such as Convolutional Neural Networks (CNN), Wave Net, an undisclosed model abbreviated as ISTM, and Recurrent Neural Networks (RNN). Our focus will be on extracting pertinent features from audio data, including short-term features like Zero Crossing Rate and Spectral Control, as well as long-term features such as Mel-Frequency Cepstral Coefficients (MFCC) and Chroma features. Through rigorous model training and optimization, we strive to create a system that delivers high accuracy and reliability in identifying synthetic speech instances. Evaluation metrics including accuracy, precision, recall, and F1-score will be employed to assess the system's performance across various datasets and real-world scenarios. Additionally, we aim to make our system adaptable to evolving synthetic speech generation techniques through continual learning mechanisms. Ultimately, our goal is to deploy the developed system in practical applications such as fraud detection, voice authentication, and content verification, contributing to enhanced security, trust, and authenticity in communication channels.
Abstract
This project delves into the challenging domain of synthetic speech detection, employing a sophisticated analysis framework that integrates short-term and long-term prediction traces. Leveraging cutting-edge deep learning methodologies such as Convolutional Neural Networks (CNN), Wave Net, an undisclosed model denoted as ISTM, and Recurrent Neural Networks (RNN), our methodology endeavors to establish a robust mechanism for identifying synthetic speech across diverse contexts. Central to our approach is the extraction of a comprehensive array of features, encompassing both short-term attributes like Zero Crossing Rate and Spectral Control, and long-term characteristics such as Mel-Frequency Cepstral Coefficients (MFCC) and Chroma features. Through meticulous data preprocessing, model training, and rigorous evaluation, our aim is to construct a system that exhibits high accuracy in discerning synthetic speech instances. This endeavor not only contributes significantly to the advancement of speech processing techniques but also holds promise for real-world applications in fraud detection, voice authentication, and content verification. By addressing the burgeoning challenge of synthetic speech detection, our project endeavors to pave the way for enhanced security measures and trustworthiness in voice-based systems and applications.
Keywords: ISTM, Synthetic speech, RNN,
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
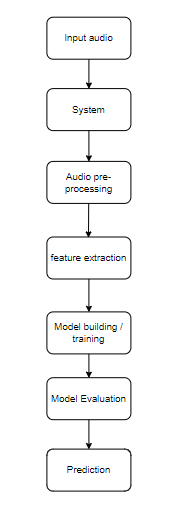
Block Diagram
Specifications
Hardware Requirements
Processor - I3/Intel Processor
Hard Disk - 160GB
Keyboard - Standard Windows Keyboard
Mouse - Two or Three Button Mouse
Monitor - SVGA
RAM - 8GB
Software
Requirements:
Operating System : Windows 7/8/10/11
Server side Script : HTML, CSS, Bootstrap & JS
Programming Language : Python
Libraries : Flask, Pandas, MySQL. Connector, Os, Smtplib, NumPy
IDE/Workbench : PyCharm or VS Code
Technology : Python 3.6+
Server Deployment : Xampp Server
Database : MySQL

Demo Video


Request for Video
 Paper Publishing
Paper PublishingRequest Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.