Speech Emotion Recognition
Objective
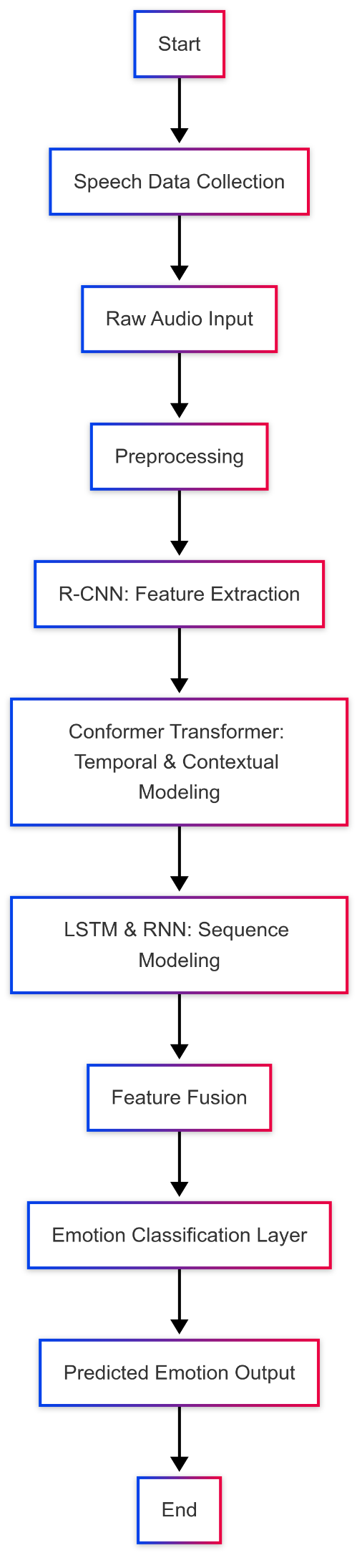
To develop a robust end-to-end deep learning framework for Speech Emotion Recognition using raw audio inputs, leveraging R-CNN, Conformer Transformer, LSTM, and RNN to enhance emotion detection accuracy and generalization.
Abstract
Speech Emotion Recognition (SER) constitutes a key aspect of affective computing and is intended to enable machines to understand and respond to human emotions in voice-based interactions. Traditional SER uses acoustic features such as MFCCs, pitch, and prosodic features, which often lack generalizability across languages, speakers, and environments. These techniques are considered very shallow in their approach to emotional changes in speech and do not account for the temporal characteristics within raw speech signals. To solve these shortcomings, the proposed study offers a novel SER framework based on end-to-end deep learning so that manual feature engineering can be avoided by directly processing raw audio inputs.
We incorporate various high-level neural networks in our architecture for a versatile and accurate emotion recognition pipeline. The heart of the system is formed by a Residual Convolutional Neural Network (R-CNN) that is used for efficient extraction of features from raw waveform data. Having residual connections alleviates the problem of vanishing gradients to some extent and allows networks to go deeper without hurting training performance. R-CNN is capable of detecting finely detailed emotional cues embedded in the raw speech signal, allowing for better generalization of the model over variations in tone, pitch, and speaker characteristics.
Conformer-Transformer is combined with the R-CNN to aid in spatial feature extraction. The model is best suited for long-term dependency and temporal relation modeling in speech. Conformer integrates convolutions and self-attention mechanisms, so the architecture incorporates both local and global contextual information. This is crucial since emotions are moving in nature, flowing through the speech rather than residing in a particular segment.
In order to improve the temporal modeling aspects in this system, it has LSTM and RNN layers. These sequential models learn the time-dependent patterns of speech data to boost emotion recognition through grasping the temporal evolution and the flow of the vocal signals. As a consequence, CNN, Transformer, LSTM, and RNN modules jointly make a robust hybrid architecture that can capture different aspects of emotion representation in speech.
The proposed model is rigorously evaluated on three publicly available SER datasets, namely RAVDESS, EMO-DB, and CREMA-D. These databases include multiple languages with a wide array of emotional classes. The experiments showed that our multi-model approach surpassed conventional baseline models and newer deep learning algorithms in accuracy, precision, recall, and F1-score. Moreover, with higher accuracy, the architectural design enabled better interpretability of emotional features owing to its hierarchical and modular structure.
The current study aims to highlight the advantages of multi-architecture deep learning-based processing of raw audio. Utilizing the strengths of R-CNNs, Conformer Transformers, LSTMs, and RNNs, our system represents a major leap in SER capabilities. The framework lays down the basis for future advancements in emotion-aware systems used for virtual assistants, mental health diagnostics, and intelligent human-computer interaction platforms..
Keywords: Speech Emotion Recognition, Affective Computing, R-CNN, Conformer Transformer, LSTM, RNN, Raw Audio Processing, Deep Learning, Temporal Modeling.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
Specifications
1 SOFTWARE REQUIREMENS
Operating System : Windows 7/8/10
Server side Script : HTML, CSS, Bootstrap & JS
Programming Language : Python
Libraries Flask, Pandas, Torch, Keras, Sklearn, Numpy , Seaborn
IDE/Workbench : VSCode
2 SOFTWARE REQUIREMENS
Technology : Python 3.6+
Server Deployment : Xampp Server
Database : MySQL
3 HARDWARE REQUIREMENTS
Processor - I3/Intel Processor
RAM - 8GB (min)
Hard Disk - 128 GB
Key Board - Standard Windows Keyboard
Mouse - Two or Three Button Mouse
Monitor - Any



 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.