Shape Penalized Decision Forests for Imbalanced Data Classification
Objective
The primary objective of this project is to develop a robust and interpretable ensemble learning framework, called Shape Penalized Decision Forests (SPDF), specifically designed for imbalanced tabular datasets. By integrating Surface-to-Volume Ratio Trees as base classifiers and penalizing irregular decision boundaries, SPDF aims to improve minority class detection without resorting to data resampling. The project seeks to enhance classification performance on highly imbalanced real-world data, such as credit card fraud detection, while maintaining dataset integrity and reducing overfitting risks common in deep learning models. Ultimately, it strives to provide smoother, more generalizable decision boundaries and reliable predictions for critical minority classes.
Abstract
Imbalanced classification remains a significant challenge in machine learning, particularly when minority classes carry critical importance, such as in fraud detection. Conventional models like Random Forest, XGBoost, and Logistic Regression often struggle with biased predictions favoring the majority class or require complex resampling techniques that may distort the data distribution. Deep learning methods, while powerful, tend to overfit small tabular datasets with limited features, reducing their effectiveness in such scenarios. Addressing these challenges, we propose Shape Penalized Decision Forests (SPDF), a novel ensemble framework designed explicitly for highly imbalanced tabular data. SPDF incorporates a modified base classifier— the Surface-to-Volume Ratio Tree (SVR-Tree)—which penalizes irregular decision boundaries rather than manipulating sample distributions. This shape-based regularization encourages smoother, more generalized decision boundaries, granting the minority class more representational space without altering the original dataset. Two variants are introduced: SPBaDF, which employs bagging with bootstrapped SVR-Trees and majority voting, and SPBoDF, which applies boosting in an AdaBoost-like manner using SVR-Trees as weak learners. Evaluated on the real-world, highly imbalanced Credit Card Fraud Detection dataset, SPDF demonstrates superior minority class recognition and interpretability compared to traditional models and oversampling techniques. By preserving dataset integrity and mitigating overfitting, SPDF offers an effective and robust alternative for imbalanced classification tasks where minority class precision is paramount.
Keywords: imbalanced classification, decision forests, surface-to-volume ratio tree, shape penalization, ensemble learning, bagging, boosting, credit card fraud detection, minority class, tabular data
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
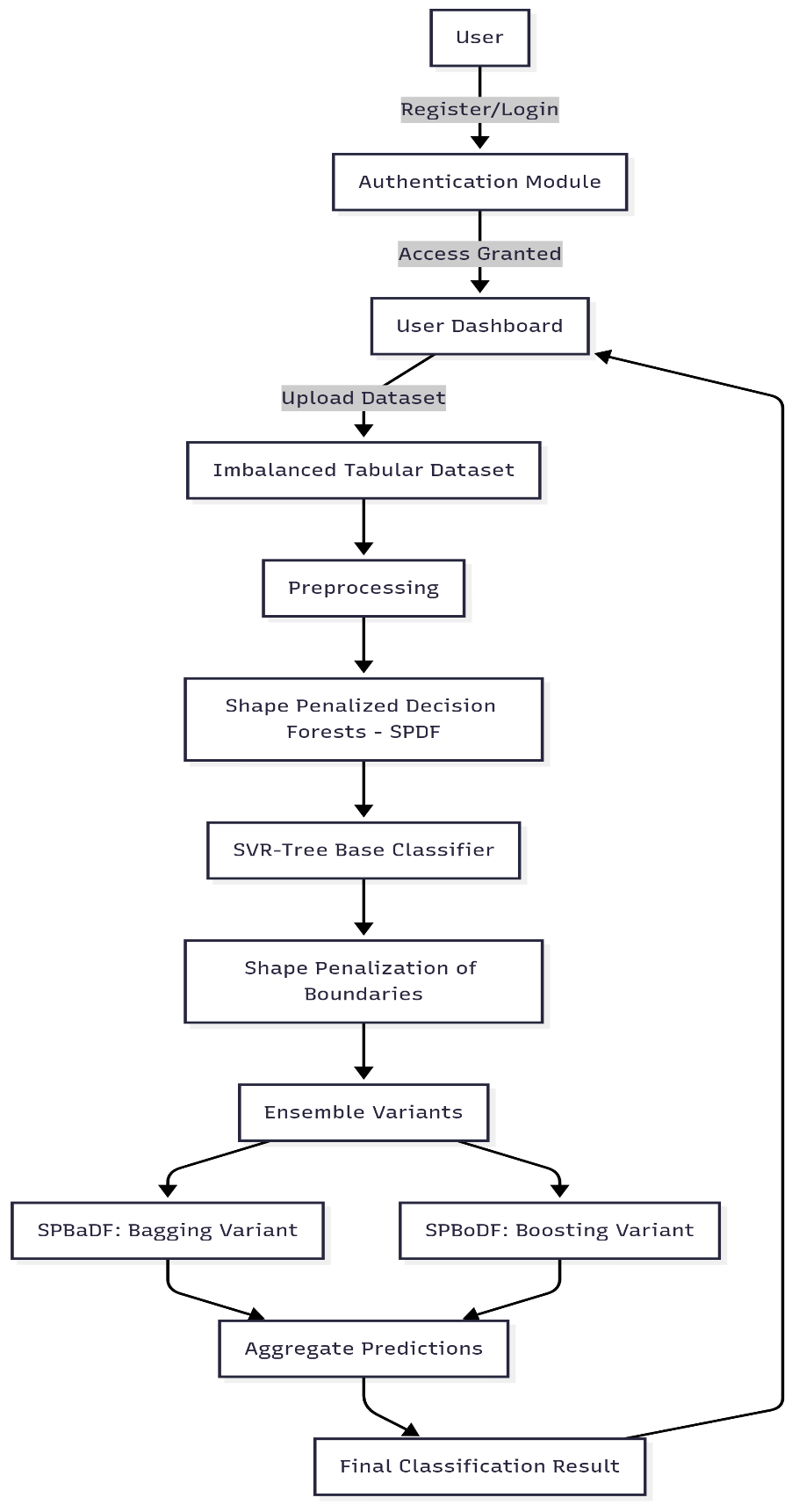
Specifications
SOFTWARE REQUIREMENS
Operating System : Windows 7/8/10
Server side Script : HTML, CSS, Bootstrap & JS
Programming Language : Python
Libraries Flask, Pandas, Torch, Keras, Sklearn, Numpy , Seaborn
IDE/Workbench : VSCode
Server Deployment : Xampp Server
Database : MySQL
HARDWARE REQUIREMENTS
Processor - I3/Intel Processor
RAM - 8GB (min)
Hard Disk - 128 GB
Key Board - Standard Windows Keyboard
Mouse - Two or Three Button Mouse
Monitor - Any

Demo Video


Request for Video
 Paper Publishing
Paper PublishingRequest Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.