Seamless textual version using Deep Learning
Objective
The objective of this project is to develop a context-aware translation system that facilitates accurate and efficient multilingual translation between Indian languages. By integrating MarianMT with BERT for contextual embeddings, the system aims to produce translations that retain grammatical accuracy and capture the intended meaning of the source text. Additional models from the HelsinkiNLP OPUSMT series extend translation support across multiple Indian languages. Incorporating speech-to-text and text-to-speech capabilities, as well as an adaptive learning component, the project further aims to support seamless spoken language translation and personalized language learning, providing a comprehensive tool for both communication and educational purposes.
Abstract
This project presents a context-aware, multilingual translation system that enhances the accuracy and fluidity of translations for multiple Indian languages. The system combines MarianMT, a robust machine translation model, with BERT for contextual understanding, enabling more accurate translations by capturing the nuances of word relationships within each sentence. Fine-tuning the MarianMT model with an English-Hindi parallel corpus further improves the model’s sensitivity to linguistic subtleties, idiomatic expressions, and cultural references unique to Hindi. Efficiency is optimized through mixed-precision training and gradient accumulation, allowing the model to handle large datasets effectively while minimizing computational overhead.
To extend functionality across Indian languages, the system incorporates models from the HelsinkiNLP OPUSMT series, accessed via the Hugging Face transformers library. This integration supports real-time translation for Hindi, Marathi, Telugu, Kannada, Tamil, Bengali, and Gujarati, bridging language barriers and enhancing communication. The system also includes speech-to-text and text-to-speech capabilities, powered by libraries like speech_recognition and gTTS, enabling seamless conversion between spoken and written language.
An adaptive learning component is introduced, utilizing machine learning algorithms to generate personalized quizzes based on user interaction and performance, promoting effective language learning. By combining advanced natural language processing with interactive educational tools, this translation system serves both as a robust language translation solution and as an innovative platform for language acquisition, applicable in educational and cross-cultural communication contexts.
Keywords: Context-aware translation, MarianMT, BERT, Indian languages, Hugging Face, speech recognition, text-to-speech, adaptive learning, natural language processing, language acquisition.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
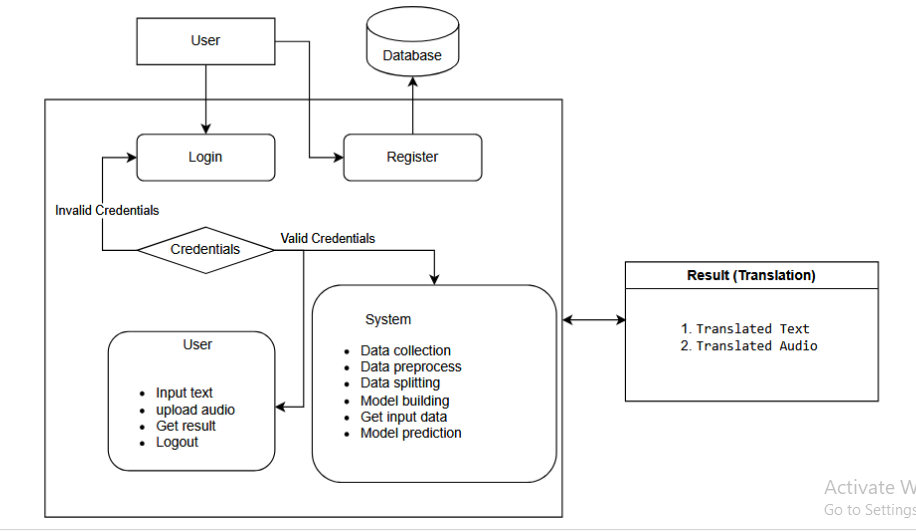
Specifications
SOFTWARE REQUIREMENS
Operating System : Windows 7/8/10
Server side Script : HTML, CSS, Bootstrap & JS
Programming Language : Python
Libraries :Flask, Torch, Tensorflow, Pandas, Mysql.connector
IDE/Workbench : VSCode
Server Deployment : Xampp Server
Database : MySQL
HARDWARE REQUIREMENTS
Processor I3/Intel Processor
RAM 8GB (min)
Hard Disk 128 GB
Key Board Standard Windows Keyboard
Mouse Two or Three Button Mouse
Monitor Any




 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.