Prediction and Explainability of School Dropout in Peru Using Machine Learning and Explainable Artificial Intelligence
Objective
This project develops an intelligent student dropout prediction framework leveraging automated machine learning and explainable AI to classify students as Dropout, Enrolled, or Graduate. The system uses Random Forest, XGBoost, CatBoost, Logistic Regression, and FLAML (AutoML) for automated model selection and hyperparameter optimization. HTSA (Hybrid Two-Stage Approach) is employed as a hierarchical framework to decompose the multiclass prediction into two sequential stages: first detecting high-risk dropout students, then distinguishing among Enrolled and Graduate students. SHAP is integrated to provide feature-level interpretability, allowing educators to identify key factors contributing to dropout risk.
Abstract
This project introduces an advanced machine learning framework designed for predicting student dropout using AutoML and SHAP (SHapley Additive exPlanations). The primary objective is to predict students' likelihood of dropping out based on various demographic, academic, and behavioral features. The system integrates AutoML for automated model selection, hyperparameter tuning, and feature engineering, making it efficient and scalable for large datasets. A key part of the process involves using SHAP to interpret model predictions, ensuring transparency in identifying which features contribute most significantly to dropout risk. The dataset comprises various student attributes, such as attendance, grades, socioeconomic status, and engagement levels, which are preprocessed through standardization and encoding techniques. SHAP values are employed to provide an interpretable explanation for individual predictions, enabling educators and administrators to understand the factors driving dropout predictions. A comparative analysis of different AutoML models was conducted, including traditional machine learning algorithms like Random Forest, SVM, and ensemble models, with the aim of improving the predictive accuracy and generalization ability of the system. The proposed framework offers a powerful tool for educational institutions to proactively identify students at risk of dropping out, enabling early intervention and personalized support. This model can be adapted to various educational contexts and contributes to improving student retention rates, advancing the field of predictive analytics in education.
Keywords: Student Dropout Prediction, AutoML, SHAP, Predictive Analytics, Machine Learning, Feature Engineering, Model Interpretability, Educational Retention, Early Intervention, Dropout Risk, Ensemble Learning, Hyperparameter Tuning, Transparent AI, Data Preprocessing, Educational Analytics.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
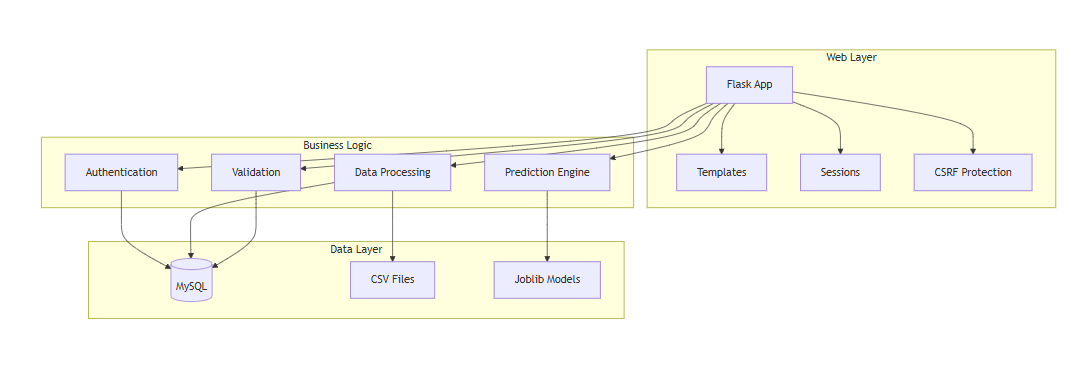
Block Diagram
Specifications
4.1 SOFTWARE REQUIREMENS
Operating System : Windows 7/8/10
Server side Script : HTML, CSS, Bootstrap & JS
Programming Language : Python
Libraries : Flask, Pandas, Sklearn, Numpy , Seaborn
IDE/Workbench : VSCODE
Server Deployment : Xampp Server
Database : MySQL
4.2 HARDWARE REQUIREMENTS
Processor - I3/Intel Processor
RAM - 8GB (min)
Hard Disk - 128 GB
Key Board - Standard Windows Keyboard
Mouse - Two or Three Button Mouse
Monitor - Any




 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.