PDF Knowledge Extraction System with RAG and CAG Models
Objective
To develop a robust PDF Knowledge Extraction System using RAG and CAG models with dual embedding pipelines and ChromaDB, enabling efficient, intelligent querying and rapid response generation for diverse documents.
Abstract
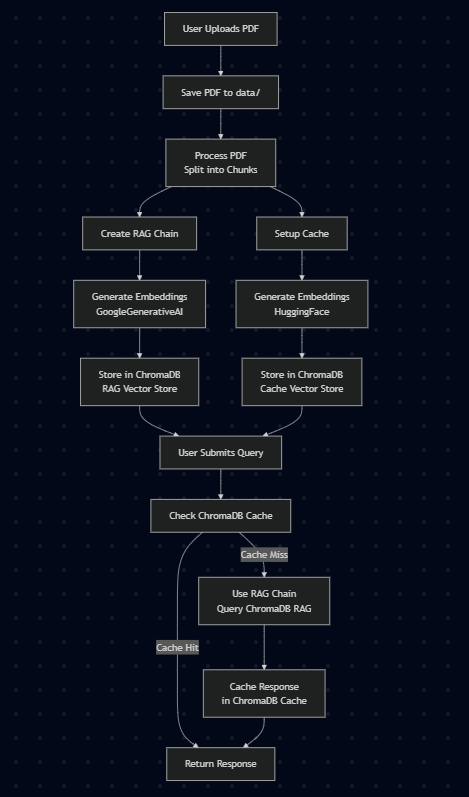
With the digital transformation of information that happened so quickly, there has been an accumulation of PDF documents through which knowledge flows. In this project, a very sturdy PDF Knowledge Extraction System was presented integrating the RAG and CAG models for intelligent and scalable document querying. It permits users to upload PDF files and then these files will be automatically parsed and segmented into chunks of content. Considered two parallel embedding pipelines: one uses Google Gemini 1.5 Flash API to generate high-quality embeddings for RAG model and the other uses HuggingFace models to cache in CAG framework.
Embeddings from both pipelines are kept in two different vector stores using
ChromaDB, which guarantees rapid retrieval and response generation. When a
query goes in, the system looks into the cache to see if any results are there.
In case of a cache hit, an appropriate answer is returned immediately with just
some milliseconds of latency. A cache miss presents where the query will be
processed via RAG as well as be cached for later requests. This hybridization
is mainly for optimized performance since RAG contributes its content awareness
while CAG supports excellent efficiency, suitable for knowledge-agent type
applications in a wide array of domains.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
Specifications
- Hardware:
- CPU: Intel i7, 16 GB RAM
- GPU: Nvidia GTX 1660 (for embedding generation and model inference)
- Disk Storage: 1TB SSD for storing PDFs and generated embeddings
- Network: 1Gbps internet connection (for API calls to Google’s Gemini 1.5 Flash API and HuggingFace models)
- Software:
- Operating System: Ubuntu 20.04
- Framework: Flask (Python)
- Embedding Generation: Google Gemini 1.5 Flash API, HuggingFace models (for contextual embeddings)
- Database: ChromaDB for storing embeddings
- Libraries: PyMuPDF for PDF text extraction, TensorFlow and PyTorch for model inference




 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.