Optimizing FPGA Logic Block Architectures for Arithmetic
Also Available Domains Arithmetic Core|Xilinx Vivado
Objective
The main objective of this paper is to reduce the power in field-programmable gate arrays (FPGAs) to improve the efficiency of arithmetic functions. In this paper, we are designing the 1-bit full adder and 4-bit CLA with the different LUT structures in FPGAs
Abstract
The term Deep Learning or Deep Neural Network refers to Artificial Neural Networks (ANN) with multi layers. Over the last few decades, it has been considered to be one of the most powerful tools, and has become very popular in the literature as it is able to handle a huge amount of data. In CNN, processing elements plays a vital role for the accelerator design.
To reduce the amount of hardware resources and power consumption, this project provides a new processing element design as an alternate solution for hardware implementation.
Modified Booth Encoding (MBE) multiplier and WALLACE tree-based adders are proposed to replace bulk MAC units and typical adder tree respectively. The synthesis and simulation are verified by using Xilinx ISE 14.7 version tool.
Keywords: Convolutional Neural Network, Booth Encoding Multiplier, WALLACE Tree Adders, Processing Elements
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
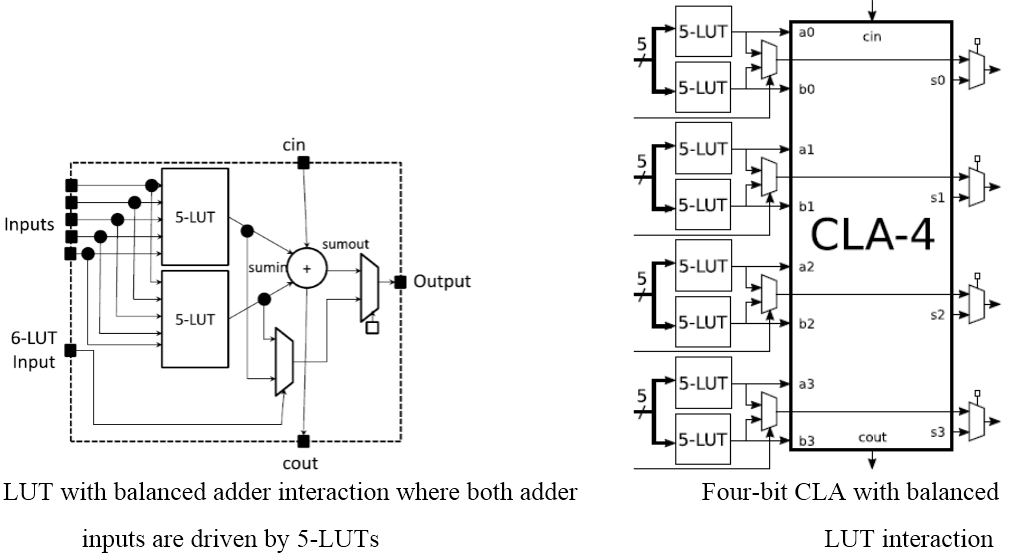
Specifications
Software Requirements:
- Xilinx ISE 14.7
- HDL: Verilog
Hardware Requirements:
- Microsoft® Windows XP
- Intel® Pentium® 4 processor or Pentium 4 equivalent with SSE support
- 512 MB RAM
- 100 MB of available disk space
Learning Outcomes
- Basics of Digital Electronics
- FPGA design Flow
- Introduction to Verilog Coding
- Different modeling styles in Verilog
- Data Flow modeling
- Structural modeling
- Behavioral modeling
- Mixed level modeling
- Combinational & Sequential circuits
- Knowledge on Arithmetic circuits
- Ripple Carry Adder
- Carry Look Ahead Adder
- About Look Up Table
- Non Fracturable Lookup Table
- Fracturable Lookup Table
- Basic Logic Elements
- Knowledge on CAD Flow
- Applications in real time
- Xilinx ISE 14.7 for design and simulation
- Generation of Netlist
- Solution providing for real time problems
- Project Development Skills:
- Problem Analysis Skills
- Problem Solving Skills
- Logical Skills
- Designing Skills
- Testing Skills
- Debugging Skills
- Presentation Skills
- Thesis Writing Skills
Demo Video


Request for Video
 Paper Publishing
Paper PublishingRequest Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.