Machine Reading Comprehension and Question-Answering Hybrid Model (BERT + Bidirectional LSTM (BiLSTM))
Objective
This project aims to develop a hybrid machine learning model that combines BERT's deep contextual analysis with LSTM's sequential data processing strengths to enhance machine reading comprehension and question answering on the SQuAD dataset. By leveraging BERT for rich contextual embeddings and LSTM for managing text sequences, the model aims to accurately predict answer spans. The primary objective is to achieve superior accuracy, precision, recall, and an improved F1 score compared to existing models, addressing the challenges of long-sequence dependencies and contextual understanding. This enhanced model has practical applications in automated customer support, educational tools, and information retrieval systems, where context-aware and accurate responses are vital. Through this project, we contribute to making AI interactions more intuitive and effective in handling complex language tasks.
Abstract
In recent advancements in natural language processing, the fusion of deep learning architectures has shown promising improvements in machine reading comprehension and question answering tasks. This study proposes a hybrid model combining the Bidirectional Encoder Representations from Transformers (BERT) with Long Short-Term Memory (LSTM) networks to leverage both context-aware embeddings generated by BERT and the sequence learning capabilities of LSTM. We utilize the Stanford Question Answering Dataset (SQuAD) as our primary dataset, which provides a robust benchmark for training and evaluating our model. The model architecture is designed to first use BERT to encode contextual relationships within the text, and then pass these embeddings to an LSTM layer that processes the sequence to predict the answer spans. Evaluation metrics, including loss and the F1 score, are used to quantify the model's performance, aiming to optimize both precision and recall of the answer predictions. Our results indicate that the hybrid model achieves superior performance compared to using each individual component alone, demonstrating the effectiveness of combining BERT with LSTM for complex question answering tasks in natural language understanding.
Keywords: Machine Reading Comprehension, Question Answering, Hybrid Model, BERT (Bidirectional Encoder Representations from Transformers), LSTM (Long Short-Term Memory), SQuAD (Stanford Question Answering Dataset), Natural Language Processing, Deep Learning, Contextual Embeddings, Sequence Learning, Model Evaluation, F1 Score, Precision and Recall, Text Understanding
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
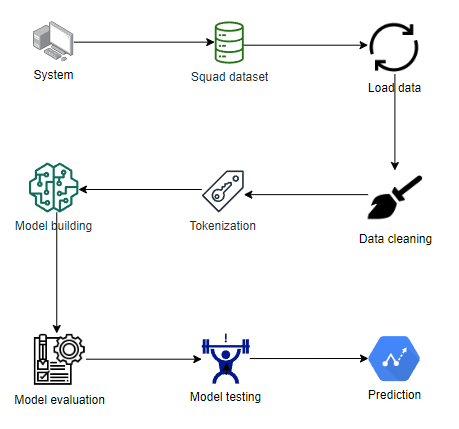
Specifications
Hardware Requirements
Processor - I3/Intel Processor
Hard Disk - 160GB
Key Board - Standard Windows Keyboard
Mouse - Two or Three Button Mouse
Monitor - SVGA
RAM - 8GB
Software Requirements:
Operating System : Windows 7/8/10
Server side Script : HTML, CSS, Bootstrap & JS
Programming Language : Python
Libraries : Flask, Pandas, Mysql.connector, Os, Smtplib, Numpy
IDE/Workbench : PyCharm
Technology : Python 3.6+
Server Deployment : Xampp Server
Database : MySQL

Demo Video


Request for Video
 Paper Publishing
Paper PublishingRequest Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.