Low Latency based Floating Point Multiplier using Parallel Prefix Adders
Objective
1. To study the principles of floating-point arithmetic and the importance of efficient multiplication in high-performance computing and digital signal processing applications. 2. To design a floating-point multiplier architecture that reduces latency by using parallel prefix adders for fast partial product summation.
Abstract
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
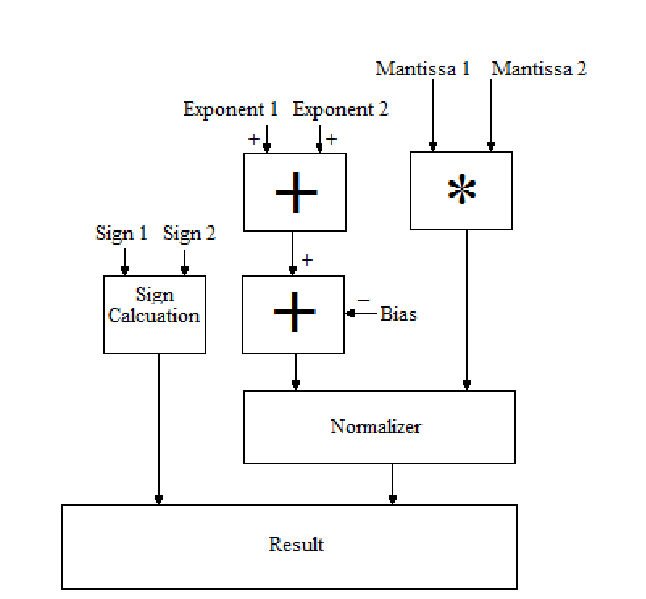
Block Diagram
Specifications
Software Requirements
- Xilinx Vivado Design Suite (2020.2 or later)
- Verilog HDL for RTL design and implementation
- Vivado Simulator (XSIM) for functional and timing verification
- MATLAB (optional) for GPR data preprocessing, noise modeling, and result validation
Hardware Requirements
- Microsoft® Windows 10 / Windows 11 (64-bit)
- Intel® Core™ i5 / i7 Processor or equivalent
- Minimum 8 GB RAM
- Minimum 500 MB free disk space
Learning Outcomes
Understanding of floating-point arithmetic and multiplier design.
Knowledge of different adder architectures (ripple-carry, CLA, PPA) and their impact on latency.
Hands-on experience in FPGA-based design and hardware optimization.
Ability to analyze trade-offs between speed, area, and power in digital circuits.
Insight into implementing high-speed arithmetic operations for DSP and scientific computing applications.



 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.