Learning Affective Video Features for Facial Expression Recognition via Hybrid Deep Learning
Abstract
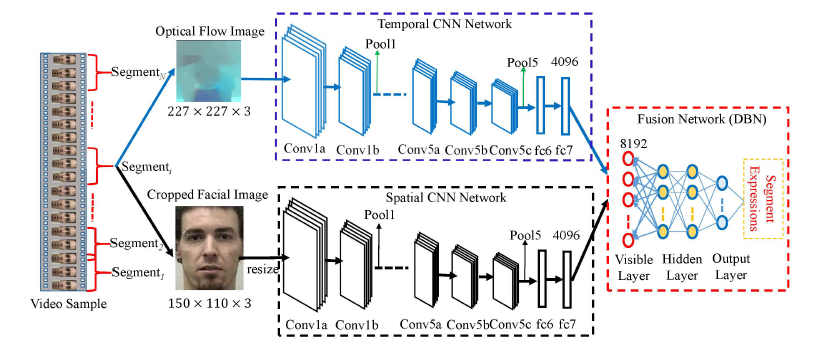
In this paper, we propose a new method of FER in video sequences via a hybrid deep learning model. One key challenging issues of facial expression recognition (FER) in video sequences is to extract discriminative spatiotemporal video features from facial expression images in video sequences. The proposed method first employs two individual deep Convolutional Neural Networks (CNN's), including a spatial CNN processing static facial images and a temporal CN network processing optical flow images, to separately learn high-level spatial and temporal features on the divided video segments. These two CNN's are ne-tuned on target video facial expression datasets from a pre-trained CNN model.
Then, the obtained segment-level spatial and temporal features are integrated into a deep fusion network built with a Deep Belief Network (DBN) model. This deep fusion network is used to jointly learn discriminative spatiotemporal features. Finally, an average pooling is performed on the learned DBN segment-level features in a video sequence, to produce a fixed-length global video feature representation. Based on the global video feature representations, a linear support vector machine (SVM) is employed for facial expression classification tasks. The extensive experiments on three public video-based facial expression datasets, i.e., BAUM-1s, RML and MMI, show the effectiveness of our proposed method, outperforming the state-of-the-arts.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
Specifications

Contact Us
- info@takeoffprojects.com
- +91 9030333433, +91 9393939065



 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.