Image Captioning Using BLIP-2 A Transformer-Based Vision Language Approach
Objective
The main objective of this project is to develop an image captioning system that leverages the pre-trained BLIP-2 model for generating descriptive captions from images. This project aims to showcase the efficiency of using pre-trained models, specifically BLIP-2, to generate accurate and contextually relevant captions without the need for further training. By utilizing the COCO-2017 dataset, the project intends to provide a system where users can easily upload images and receive descriptive captions in return. The goal is to create a user-friendly interface with functionalities like Home, Register, Login, Caption, History, and Logout. Additionally, the project will focus on evaluating the effectiveness of BLIP-2 in caption generation, analyzing how well the model can handle diverse types of images and produce coherent captions. By achieving these objectives, the project aims to improve the interaction between visual and textual data, creating a scalable solution that can be applied in areas like content accessibility, digital media management, and more. Ultimately, the project seeks to demonstrate the potential of pre-trained models in simplifying and accelerating tasks traditionally requiring intensive training and computational resources.
Abstract
Image captioning is an essential task in the intersection of computer vision and natural language processing, where the goal is to automatically generate descriptive text based on the visual content of images. This project leverages the power of the pre-trained BLIP-2 model, a cutting-edge transformer-based model, to generate captions from images. The dataset used for this task is the COCO-2017 dataset, known for its diverse collection of images and corresponding textual annotations. By utilizing the BLIP-2 model, this system efficiently generates captions without requiring extensive computational resources for training. The focus is on utilizing a pre-trained model that already understands the intricate relationship between visual data and language, making the captioning process fast and accessible. The application allows users to upload images, which are then processed by the BLIP-2 model to produce relevant, descriptive captions. This solution presents an effective approach to automating image description, making it useful for a variety of applications, from enhancing accessibility for visually impaired individuals to improving image-based content categorization. The simplicity and efficiency of using a pre-trained model open up new possibilities for practical deployment in multiple domains.
Keywords: Image captioning, BLIP-2, Pre-trained model, COCO-2017 dataset, Transformer-based architecture, Visual data understanding, Natural language generation, Caption generation, Image-text interaction, Efficient image description.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
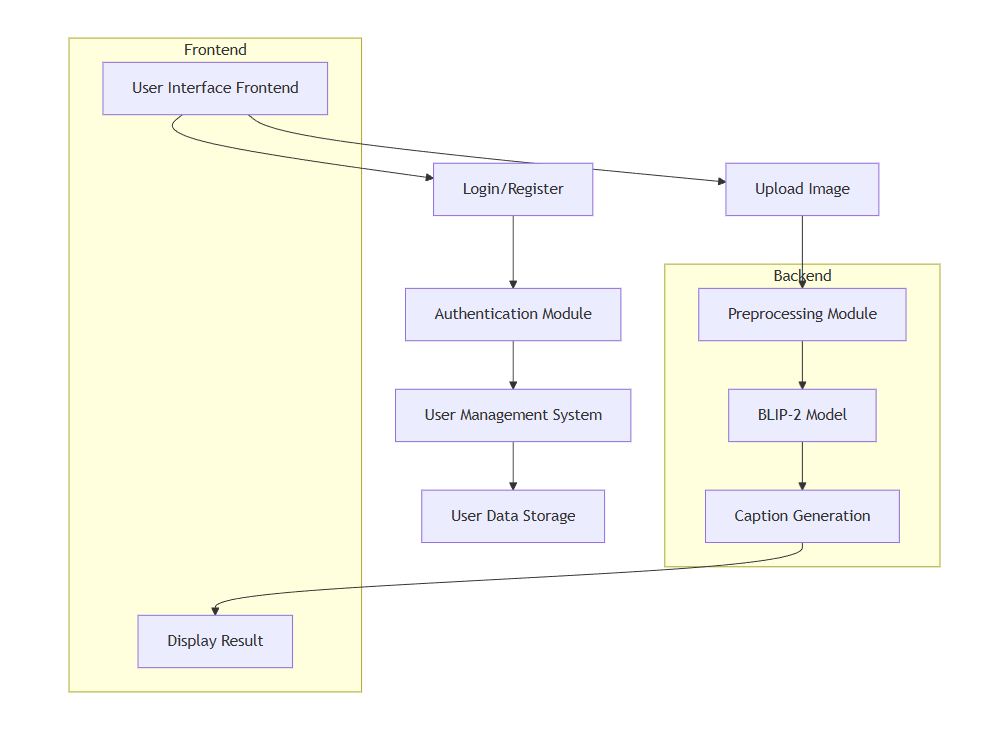
Block Diagram
Specifications
3.1 Hardware Requirements
Processor - I3/Intel Processor
Hard Disk - 160GB
Key Board - Standard Windows Keyboard
Mouse - Two or Three Button Mouse
Monitor - SVGA
RAM - 8GB
3.2 Software Requirements
Operating System : Windows 7/8/10
Programming Language : Python
Libraries : Pandas, Numpy, scikit-learn.
IDE/Workbench : Visual Studio Code.
Framework : Django




 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.