Image Caption Generator using CNN and LSTM
Objective
The primary objective of this project is to develop a robust and accurate automatic image captioning system using advanced deep learning techniques. This involves implementing a multimodal model that effectively integrates visual features extracted by the ResNet50 convolutional neural network with sequential information processed by long short-term memory networks (LSTMs). The specific objectives include preprocessing and cleaning the caption dataset, creating word-to-index and index-to-word mappings, obtaining word embeddings from GloVe, and training the model to generate coherent and contextually relevant captions. Evaluation will be conducted using established metrics like BLEU scores to assess the model's performance. Additionally, the project aims to contribute to the field by providing insights into the challenges and advancements in image captioning, showcasing its practical applications, and potentially laying the foundation for further research in multimodal AI systems.
Abstract
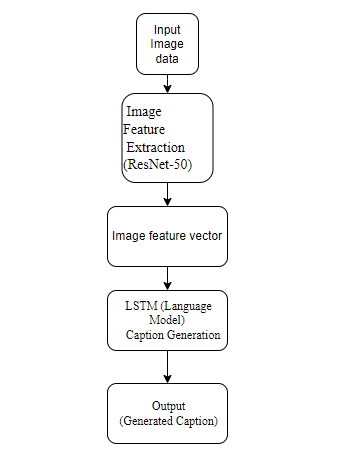
The provided script implements an image captioning model using the image dataset. The architecture combines a ResNet50 convolutional neural network (CNN) for image feature extraction and a long short-term memory network (LSTM) for processing word sequences. After reading and cleaning captions, the script preprocesses the data, extracts image features using ResNet50, and prepares the training and test datasets. The model is designed to predict captions given an image, and it incorporates word embedding’s from Glove. The script also involves creating word-to-index and index-to-word mappings, defining the model architecture, and training the model using a generator for data loading. The training utilizes a combination of image features and word sequences, and the model is evaluated using BLEU scores on test images. The overall approach reflects a deep learning paradigm for image captioning, leveraging both visual and linguistic information to generate descriptive captions. The ResNet50 CNN serves as a powerful feature extractor, and the LSTM captures sequential dependencies in language, resulting in a comprehensive image captioning model.
KEYWORDS: CNN, Resnet-50, image caption generation, LSTM.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
Specifications
H/W CONFIGURATION:
Processor - I3/Intel Processor
Hard Disk - 160GB
Key Board - Standard Windows Keyboard
Mouse - Two or Three Button Mouse
Monitor - SVGA
RAM - 8GB
S/W CONFIGURATION:
Operating System : Windows 7/8/10
Server side Script : HTML, CSS, Bootstrap & JS
Programming Language : Python
Libraries : Flask, Pandas, Mysql.connector, Os, Smtplib, Numpy
IDE/Workbench : PyCharm
Technology : Python 3.6+
Server Deployment : Xampp Server




 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.