Heart Disease Detection using Audio Dataset
Objective
The objective of this project is to develop an audio-based system for the early detection and classification of heart disease by analyzing heart sound recordings. The system aims to classify heart sounds into two categories: "Healthy" and "Unhealthy." By leveraging deep learning models such as CNN, RCNN, ResNet50, VGG16, and MobileNet, the project seeks to accurately detect heart disease based on audio features extracted from heart sounds. The goal is to provide a non-invasive, efficient, and cost-effective tool for early-stage heart disease diagnosis, which could potentially reduce the reliance on more complex and expensive diagnostic procedures.
Abstract
Heart disease detection plays a critical role in the early diagnosis and management of cardiovascular diseases. This study explores the application of audio-based methods for heart disease detection using a dataset of heart sounds. Sourced from Kaggle, the dataset consists of labeled heart sound recordings categorized as either "Healthy" or "Unhealthy." The proposed approach employs a range of deep learning models, including Convolutional Neural Networks (CNN), Recurrent Convolutional Neural Networks (RCNN), ResNet50, VGG16, and MobileNet, for effective classification of heart sounds.
For feature extraction, we utilize Mel-frequency cepstral coefficients (MFCC), a robust technique widely used in speech and audio processing for capturing the spectral characteristics of heart sounds. To improve model robustness and generalization, we enhance the dataset with techniques such as noise augmentation, pitch shifting, Zero-Crossing Rate (ZCR), and Root Mean Square Error (RMSE). These methods help address variations in heart sound recordings caused by environmental factors or physiological changes.The CNN and RCNN models, in combination with advanced architectures like ResNet50, VGG16, and MobileNet, are trained to classify heart sounds into "Healthy" and "Unhealthy" categories.
Keywords: Heart disease detection, audio dataset, Kaggle, heart sound classification, CNN, RCNN, ResNet50, VGG16, MobileNet, MFCC, noise augmentation, pitch shifting, ZCR, RMSE, feature extraction, deep learning, machine learning, cardiovascular disease, audio-based diagnosis.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
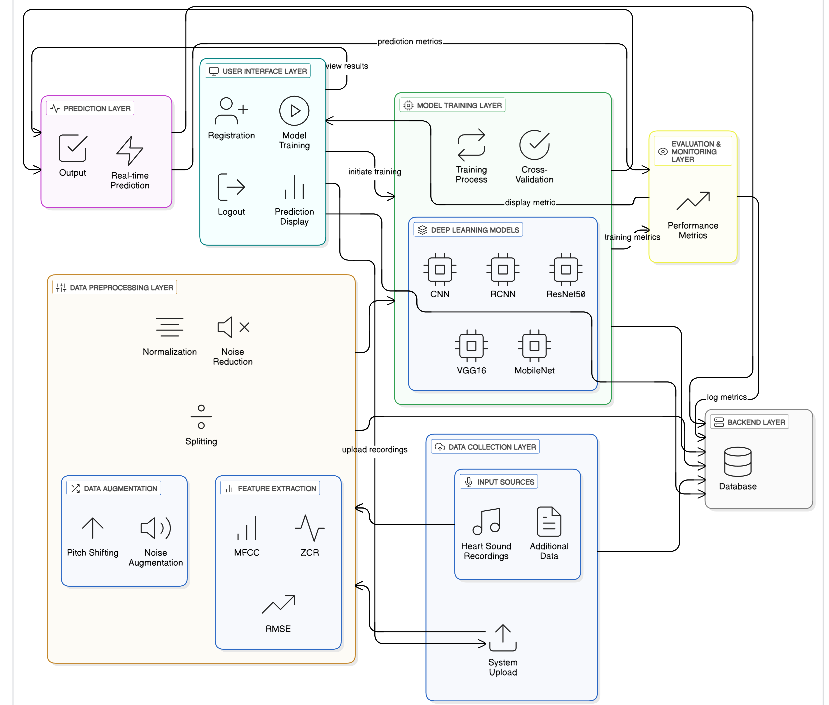
Specifications
SOFTWARE REQUIREMENS
Operating System : Windows 7/8/10
Server side Script : html,css,js
Programming Language : Python
Libraries : Django, Pandas, Torch, Keras, Sklearn, Numpy , Seaborn
IDE/Workbench : VSCode
Server Deployment : Xampp Server
Database : SQLite
HARDWARE REQUIREMENTS
Processor - I3/Intel Processor
RAM - 8GB (min)
Hard Disk - 128 GB
Key Board - Standard Windows Keyboard
Mouse - Two or Three Button Mouse
Monitor - Any




 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.