File De Duplication
Objective
The primary goal of this project is to find the duplicate data that is entered into the database.
Abstract
At present, data de-duplication on the metadata management and read/write rate. In order to achieve higher de-duplication elimination ratio, the traditional way is to expand the range of data for data de-duplication, but that would make metadata fields longer and increase the number of metadata entries. When detecting the redundant data, metadata needs to be constantly imported and exported into the memory and access bottleneck will be produced. So it is necessary to detect similar documents to classify valuable data for de-duplication. In this paper, we propose a new method of block-level data de-duplication combined with similar file detection. At the time of guaranteeing the de-duplication elimination ratio, we narrow the range of data to reduce the metadata and eliminate performance bottlenecks. We present a detailed evaluation of our method and other existing data deduplication methods, and we show that our method meets its design goals as it improves the de-duplication ratio while reducing overhead costs.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
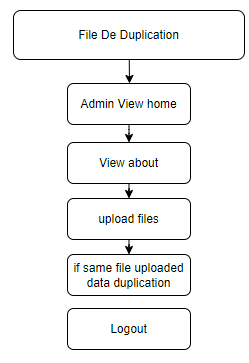
Specifications
H/W CONFIGURATION:
Processor - I3/Intel Processor
Hard Disk - 160GB
Key Board - Standard Windows Keyboard
Mouse - Two or Three Button Mouse
Monitor - SVGA
RAM - 8GB
S/W CONFIGURATION:
Operating System : Windows 7/8/10
Server side Script : HTML, CSS, Bootstrap & JS
Programming Language : Python
Libraries : Flask, Pandas, Mysql.connector, Os, Smtplib, Numpy
IDE/Workbench : PyCharm
Technology : Python 3.6+
Server Deployment : Xampp Server




 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.