Enhancing Speech Emotion Recognition with Deep Learning Techniques
Objective
The objective of this study is to develop an advanced Speech Emotion Recognition (SER) algorithm that leverages raw speech data to improve emotion detection accuracy, eliminating the reliance on manually selected acoustic features. By integrating a Residual Convolutional Neural Network (R-CNN), Conformer Transformer, Long Short-Term Memory (LSTM), and Recurrent Neural Network (RNN) models, the approach aims to capture both emotional and temporal features in speech. The goal is to enhance emotion classification by combining deep learning techniques that process raw audio, detect subtle emotion-driven cues, and improve model interpretability, thereby advancing affective computing in diverse linguistic contexts.
Abstract
Recent advancements in speech emotion recognition (SER) have primarily centered on effective feature selection from acoustic data. This study introduces a novel SER algorithm that leverages raw speech data to enhance recognition accuracy, eliminating the need for manually selected acoustic features. Our approach integrates a Residual Convolutional Neural Network (R-CNN) model to detect emotions directly from raw speech signals and a Conformer Transformer model to capture long-range dependencies and temporal features in speech. The R-CNN model processes the raw audio, extracting emotional cues for accurate classification without relying on pre-selected acoustic features, thus capturing subtle emotion-driven nuances that traditional methods may overlook. Simultaneously, the Conformer Transformer model processes speech data to learn complex representations of the emotional content. Additionally, Long Short-Term Memory (LSTM) and Recurrent Neural Network (RNN) models are utilized to capture the sequential nature of speech signals, further enhancing the emotion recognition process. Evaluated across three public datasets in multiple languages, the proposed model demonstrates a notable improvement in accuracy and interpretability by leveraging both emotional and temporal information. This approach highlights the benefits of a multi-model framework that combines deep learning architectures, pushing the boundaries of affective computing through a more holistic understanding of speech data.
Keywords: Affective Computing, Speech Emotion Recognition, Deep Learning, CNN, LSTM, RNN, Conformer Transformer, Interpretability.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
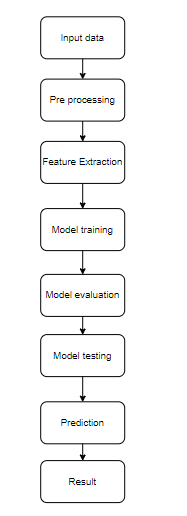
Block Diagram
Specifications
1 SOFTWARE REQUIREMENS
Operating System : Windows 7/8/10
Server side Script : HTML, CSS, Bootstrap & JS
Programming Language : Python
Libraries Flask, Pandas, Torch, Keras, Sklearn, Numpy , Seaborn
IDE/Workbench : VSCode
2 SOFTWARE REQUIREMENS
Technology : Python 3.6+
Server Deployment : Xampp Server
Database : MySQL

Demo Video


Request for Video
 Paper Publishing
Paper PublishingRequest Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.