Enhancing Random Forest Using Genetic Algorithm for Lifelong Machine Learning
Objective
This project aims to develop an intelligent credit risk classification system that uses advanced machine learning techniques to help financial institutions accurately assess borrower risk based on financial behavior patterns extracted from credit data. By leveraging high-performing models such as Random Forest, XGBoost, Stacking Ensemble, Multi-Layer Perceptron, and a novel Genetic Algorithm-driven Evolutionary Random Forest, the system classifies applicants into Good or Bad credit risk categories using 28 critical financial indicators, including external risk estimates, trade history, delinquency patterns, and credit utilization metrics. The framework is designed to deliver highly accurate risk predictions that support informed lending decisions, improve loan approval strategies, and reduce financial losses. It also performs comprehensive financial data analysis to identify influential risk factors and areas requiring intervention for effective risk mitigation. A key innovation of the project is the incorporation of a GA-driven continual learning mechanism with tree-level knowledge retention, enabling the model to adapt to new financial data over time while minimizing catastrophic forgetting. Through rigorous evaluation using metrics such as accuracy, precision, recall, and F1-score, the system ensures reliable and scalable performance, making it a robust, adaptive, and continuously improving solution for modern credit risk assessment.
Abstract
This project presents a novel machine learning framework for the automated classification of credit risk using the Home Equity Line of Credit (HELOC) dataset. The system is designed to distinguish between "Good" and "Bad" risk performance for loan applicants. The methodology involved a comprehensive data preprocessing pipeline, including label encoding of categorical variables, feature scaling, and exploratory data analysis (EDA) to understand feature correlations and class distributions. Initial data analysis revealed a dataset of 30,000 entries with 28 mixed-type features, comprising both numerical credit indicators and categorical demographic variables (e.g., CreditGrade, EmploymentStatus, HomeOwner). A critical step was the implementation of a Genetic Algorithm (GA) -Driven Evolutionary Random Forest (GA-ERF), which introduces a novel concept of "tree-level knowledge retention" to mitigate catastrophic forgetting—a key challenge in lifelong and continual learning systems without relying on neural networks. A comparative analysis of different modeling approaches was planned, focusing on the proposed evolutionary Random Forest, with the goal of leveraging ensemble learning to capture complex, non-linear patterns in the credit data. The preprocessing pipeline utilized label encoding to convert categorical variables into a machine-readable format, and the analysis highlighted a class imbalance in the target variable (RiskPerformance), as visualized in a count plot. The model's predictive performance was evaluated for its ability to automate credit risk analysis, providing a potentially powerful tool for financial institutions, loan officers, and risk assessors. By combining the robustness of Random Forests with an evolutionary mechanism designed for continual learning, GA-ERF aims to offer a superior and more adaptable solution for monitoring financial risk and adapting to new credit patterns over time. The inclusion of innovative learning strategies, such as the GA-driven optimization for knowledge retention, highlights the project's aim to push the boundaries of predictive analytics in geospatial and financial intelligence for sustainable economic development.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
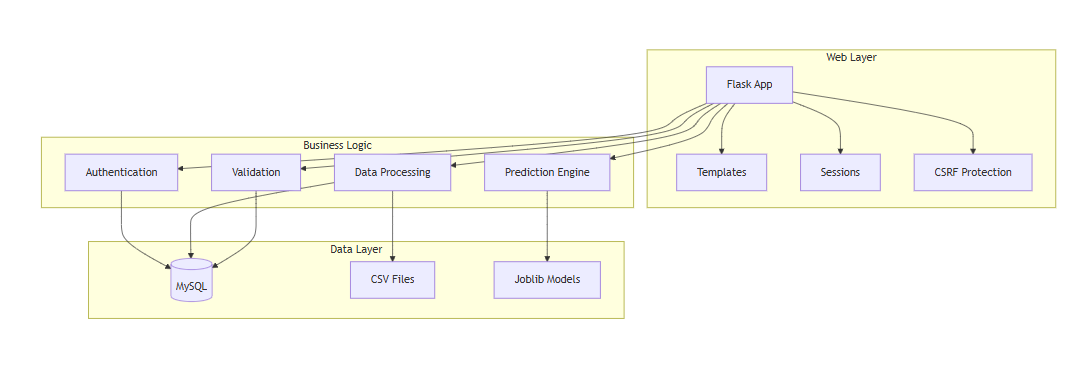
Specifications
4.1 SOFTWARE REQUIREMENS
Operating System : Windows 7/8/10
Server side Script : HTML, CSS, Bootstrap & JS
Programming Language : Python
Libraries : Flask, Pandas, Sklearn, Numpy , Seaborn
IDE/Workbench : VSCODE
Server Deployment : Xampp Server
Database : MySQL
4.2 HARDWARE REQUIREMENTS
Processor - I3/Intel Processor
RAM - 8GB (min)
Hard Disk - 128 GB
Key Board - Standard Windows Keyboard
Mouse - Two or Three Button Mouse
Monitor - Any




 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.