Enhancing Coffee Leaf Disease Classification via Active Learning and Diverse Sample Selection
Objective
The objective of this project is to develop an coffee leaf disease classification system using deep learning models. The system aims to accurately predict various coffee leaf diseases based on uploaded images from the Rocole – A Robusta Coffee Leaf Images Dataset (Kaggle), which includes classes like Healthy, Leaf Rust and red_spider_mite. It utilizes models such as VGG16, DenseNet, MobileNet, and Swin Transformer for disease classification. Active learning will be integrated to reduce the need for large labeled datasets while maintaining high accuracy. The project seeks to provide farmers with a user-friendly tool for early disease detection to improve crop health and yield.
Abstract
This project presents a hybrid deep learning framework for enhancing coffee leaf disease classification using a combination of advanced models such as VGG16, DenseNet, MobileNet, and Swin Transformer. The proposed system classifies coffee leaf images into distinct disease categories, leveraging the strengths of each model. The VGG16 model achieves a validation accuracy of 91.93%, DenseNet reaches 93.17%, MobileNet also achieves 93.17%, and the Swin Transformer model achieves 92.55%. Each model contributes to capturing key image features, with VGG16 focusing on hierarchical image patterns, DenseNet enhancing feature reuse, MobileNet providing a lightweight solution, and Swin Transformer improving contextual learning and long-range dependency extraction. Active learning and diverse sample selection strategies further enhance the accuracy and generalization of the model. A Flask-based web application is developed with modules for Home, Register, Login, Classification, and Logout, providing a seamless user experience. The integration of these models demonstrates a robust approach to improving coffee leaf disease classification performance and feature representation.
Keywords: Swin Transformer, Coffee Leaf Disease, Deep Learning, VGG16, DenseNet, MobileNet, Active Learning, Image Classification.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
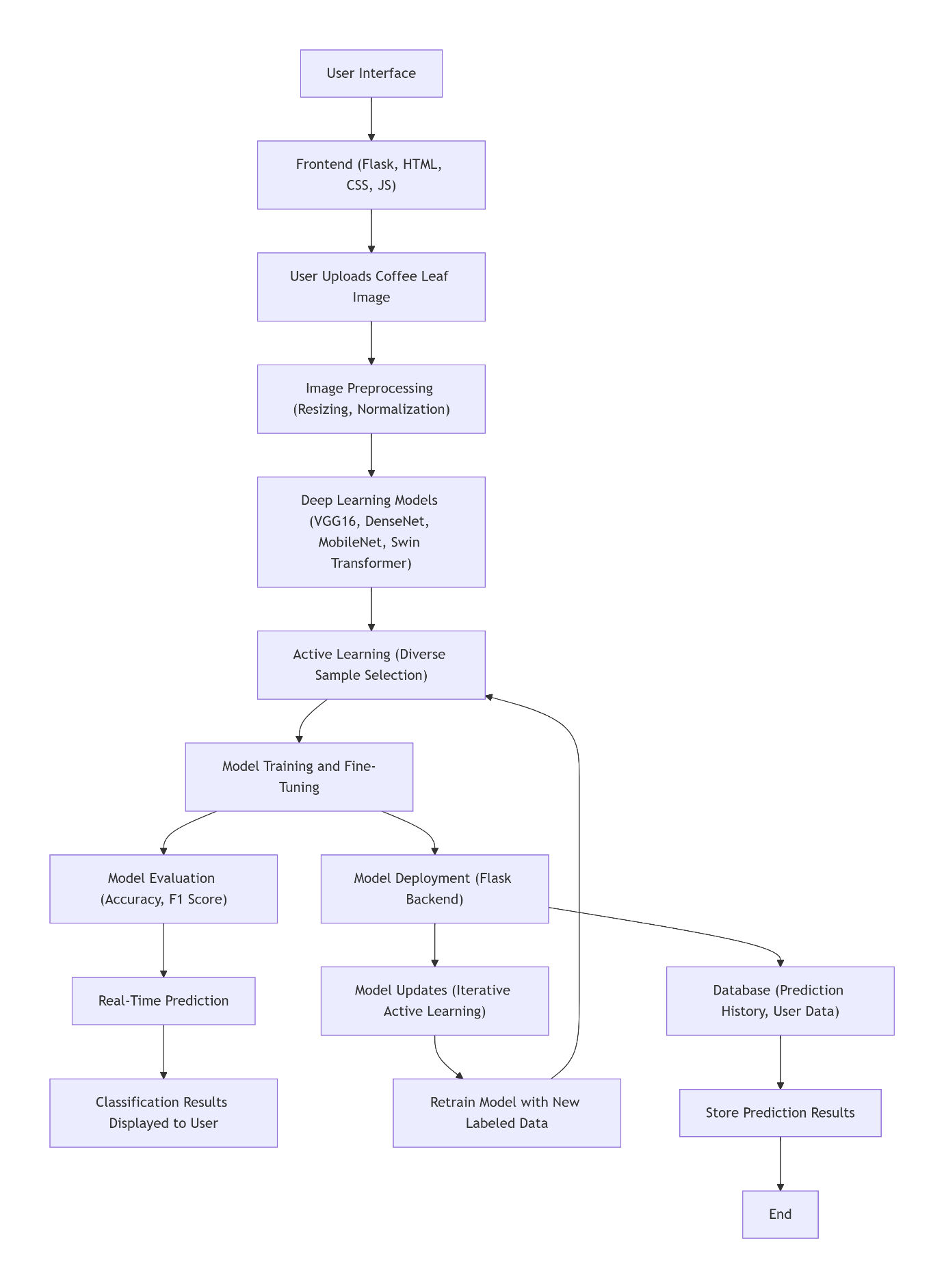
Specifications
Hardware Requirements
The hardware requirements specify the physical resources necessary to run the system effectively. For this project, the following are the recommended hardware specifications:
· Processor: Intel Core i5 or better (Preferably multi-core for faster processing)
· Hard Disk: 500GB SSD or higher (For faster data access and storage of large image datasets)
· RAM: 16GB or more (To handle the memory-intensive operations of deep learning models)
· Graphics Card: NVIDIA GTX 1060 or higher (For accelerating deep learning model training and inference)
· Keyboard: Standard Windows Keyboard (For basic system interaction)
· Mouse: Two or Three Button Mouse (For navigation within the system)
· Monitor: Full HD (1920x1080) or higher resolution (For clear visualization of results and system output)
· Internet: Stable internet connection (For accessing external datasets and model updates)
Software Requirements
The software requirements specify the environment and tools necessary to develop, run, and deploy the system. The required software components for this project are as follows:
· Operating System: Windows 7/8/10 or Linux (Ubuntu recommended for development)
· Programming Language: Python 3.8 or higher
· Libraries:
o TensorFlow/Keras: For deep learning model development and training.
o PyTorch: For training deep learning models, especially Swin Transformer and MobileNet.
o Pandas: For data manipulation, preprocessing, and analysis.
o NumPy: For numerical operations and handling multidimensional arrays.
o scikit-learn: For machine learning algorithms, model evaluation, and performance metrics.
o Flask: For backend development of the web application.
o OpenCV: For image processing tasks like resizing and normalization.
o Matplotlib/Seaborn: For data visualization, including model evaluation and performance plotting.
o Faiss: For efficient similarity search, particularly for diverse expansion sampling.
· IDE/Workbench: Visual Studio Code, PyCharm, or Jupyter Notebooks for development and testing.
· Database: MySQL or SQLite for storing user data, prediction history, and model results.




 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.