Dysarthria Detection Using Audio Analysis
Objective
The project begins with data collection and preprocessing, where speech samples from the "noise-reduced-uaspeech-dysarthria-dataset" are gathered. The data is cleaned by removing noise, normalizing the volume, and segmenting the speech to enhance both the quality and accuracy of the model. For model development, deep learning architectures such as CNN + LSTM, CNN + GRU, and Wave2vec are employed to classify speech disorders, focusing on learning both temporal and spectral features from the data. The performance of each model is then evaluated using metrics like accuracy, precision, recall, and F1-score to determine the best model for the task. To facilitate user interaction, a simple web interface is designed using HTML, CSS, and JS, with Flask powering the backend. This allows users to upload speech recordings and receive automatic classification results. Finally, the trained models are integrated into the web application for real-time classification, providing users with quick and accurate results.
Abstract
Speech disorders, particularly dysarthria, are speech impairments resulting from neurological conditions that affect muscle control needed for clear speech. Detecting these disorders at an early stage is crucial for proper intervention, yet manual diagnosis can be time-consuming and challenging. This project aims to automate the classification of speech disorders using deep learning models, specifically convolutional neural networks (CNN) combined with recurrent neural networks (RNNs) like LSTM (Long Short-Term Memory) and GRU (Gated Recurrent Units), as well as the Wave2vec model. The dataset utilized for training the models is the "noise-reduced-uaspeech-dysarthria-dataset," which contains speech samples with varying levels of dysarthria severity. The deep learning models are trained to extract temporal and spectral features from these speech samples, enabling accurate classification. This project involves developing a web application that allows users to upload speech recordings for automated classification of dysarthria, providing quick and reliable results. The primary goal of this project is to build a robust model that can identify different speech disorders based on speech features, assisting healthcare professionals in early detection and diagnosis.
Keywords: Speech disorder, dysarthria, deep learning, convolutional neural network, recurrent neural network, LSTM, GRU, Wave2vec, classification, healthcare.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
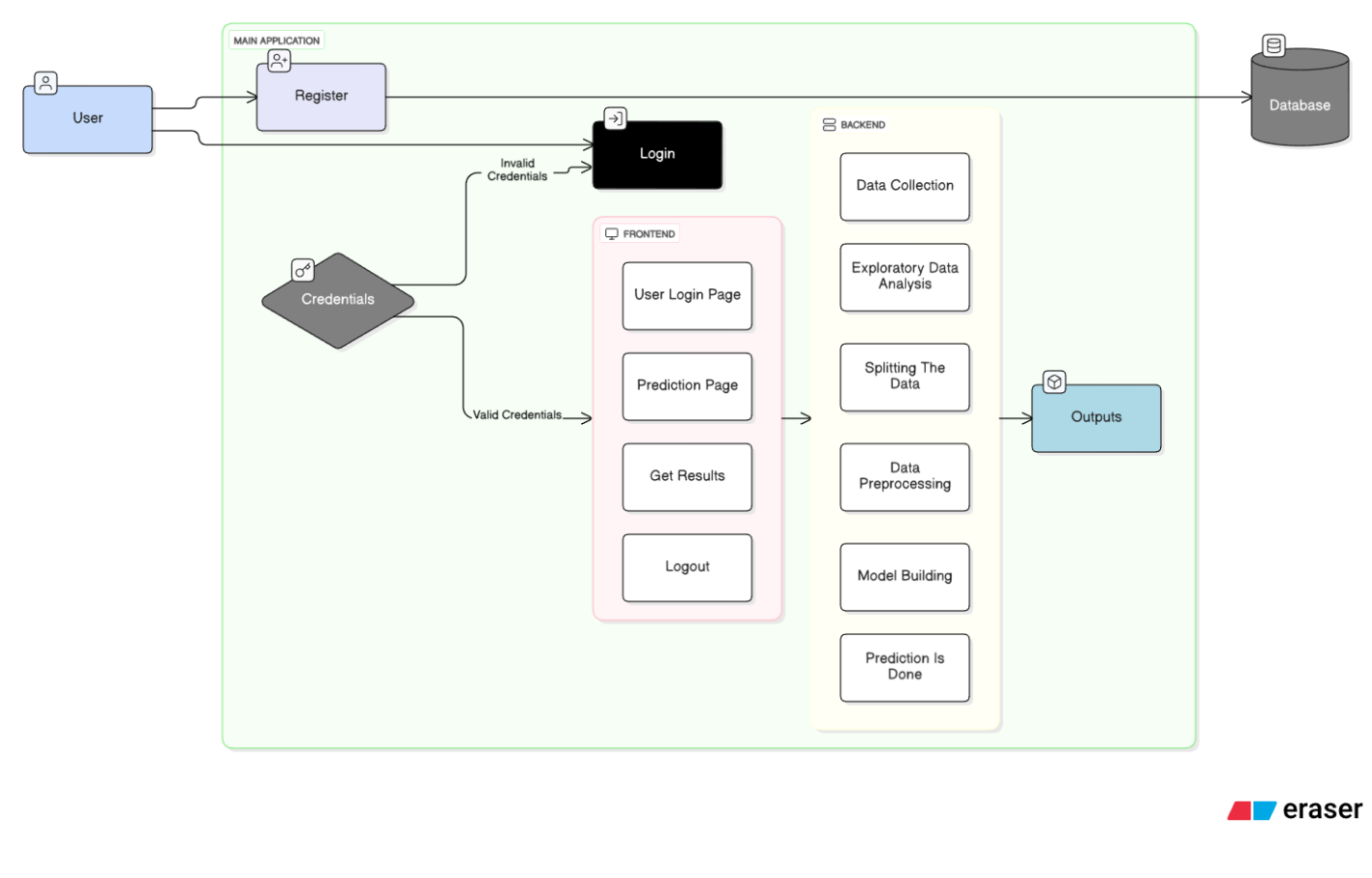
Specifications
Hardware Requirements
Processor - I3/Intel Processor
Hard Disk - 160GB
Key Board - Standard Windows Keyboard
Mouse - Two or Three Button Mouse
Monitor - SVGA
RAM - 8GB
Software Requirements:
Operating System : Windows 7/8/10
Server side Script : HTML, CSS, Bootstrap & JS
Programming Language : Python
Libraries : Flask/Django, Pandas, Mysql.connector, Os, Smtplib, Numpy
IDE/Workbench : PyCharm
Technology : Python 3.6+
Server Deployment : Xampp Server
Database : MySQL




 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.