Dynamic Selection an Classifier for Software Fault Prediction
Objective
The main goal of this analysis study is to use machine learning algorithms to predict whether the software is fault or not. And we have ability to implement different models to predict.
Abstract
In the last decades, the research community has devoted a lot of effort in the definition of approaches able to predict the defect proneness of source code files. Such approaches exploit several predictors (e.g., product or process metrics) and use machine learning classifiers to predict classes into buggy or not buggy, or provide the likelihood that a class will exhibit a fault in the near future. The empirical evaluation of all these approaches indicated that there is no machine learning classifier providing the best accuracy in any context, highlighting interesting complementarity among them. For these reasons ensemble methods have been proposed to estimate the bug-proneness of a class by combining the predictions of different classifiers. Following this line of research, in this paper we propose an adaptive method, named ASCI (Adaptive Selection of Classifiers in bug prediction), able to dynamically select among a set of machine learning classifiers the one which better predicts the bug-proneness of a class based on its characteristics. An empirical study conducted on 30 software systems indicates that ASCI exhibits higher performances than five different classifiers used independently and combined with the majority voting ensemble method.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
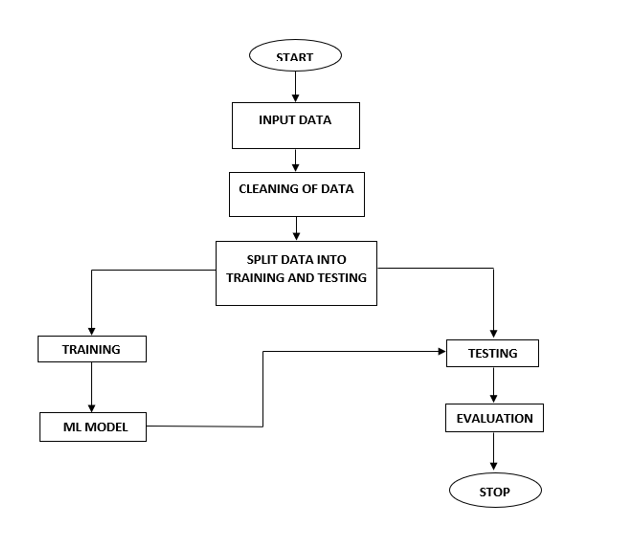
Specifications
HARDWARE SPECIFICATIONS:
- Processor: I3/Intel
- Processor RAM: 4GB (min)
- Hard Disk: 128 GB
- Key Board: Standard Windows Keyboard
- Mouse: Two or Three Button Mouse
- Monitor: Any
SOFTWARE SPECIFICATIONS:
- Operating System: Windows 7+
- Server-side Script: Python 3.6+
- IDE: Jupyter
- Libraries Used: Pandas, Numpy.
Learning Outcomes
- About Python.
- About Pandas.
- About Numpy.
- About Sklearn.
- About Machine Learning.
- About Artificial Intelligent.
- About how to use the libraries.
- Cloud Overview.
- Virtualization.
- About how to create the registration table in sql.
- About model choosing.
- About how to generate the predictions with python code.
- Project Development Skills:
- Problem analyzing skills.
- Problem solving skills.
- Creativity and imaginary skills.
- Programming skills.
- Deployment.
- Testing skills.
- Debugging skills.
- Project presentation skills.
- Thesis writing skills.



Related Projects
 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.