Detecting Deepfake Audio Using Spectrogram-Based Machine Learning Approaches
Objective
The objective of this project is to accurately detect and classify deepfake audio using spectrogram-based machine learning approaches. The primary goal is to develop an automated system that can differentiate between fake and real audio recordings with high precision. By leveraging advanced deep learning models, including Convolutional Neural Networks (CNN), EfficientNet, and CNN-GRU hybrid models, this project aims to detect manipulated audio content that could potentially mislead listeners or harm the integrity of media. The system will analyze spectrograms of audio signals, allowing for accurate classification of the audio as either Fake or Real. The ultimate goal is to provide a reliable solution for identifying deepfake audio, offering valuable insights into the growing issue of AI-generated fake content.
Abstract
Deepfake audio has emerged as a significant threat in the digital age, with the potential to deceive listeners and cause harm in various sectors, such as media, security, and social networks. This project focuses on detecting deepfake audio using spectrogram-based machine learning approaches. The system leverages four powerful machine learning algorithms: Convolutional Neural Networks (CNN), EfficientNet, CNN-GRU, and a hybrid CNN-GRU model. These models are applied to spectrogram representations of audio signals, which convert time-domain audio data into visual forms, enabling the models to detect subtle differences between real and fake audio. The CNN and EfficientNet models are utilized to extract features from the spectrograms, while the CNN-GRU hybrid model combines the strengths of CNN for feature extraction and GRU for temporal sequence learning. The project aims to classify audio as either Fake or Real, providing a robust framework for detecting manipulated audio content. The models are trained and evaluated using Python and libraries such as TensorFlow and Keras for deep learning, with performance metrics including accuracy, precision, recall, and F1-score. The goal of this project is to offer a scalable, real-time solution for detecting deepfake audio, addressing the increasing concern over misinformation and malicious use of AI-generated content. By combining deep learning techniques and advanced feature extraction methods, this project emphasizes the growing need for robust detection systems in combating digital audio manipulation.
Keywords: Deepfake Audio, Spectrogram, Machine Learning, CNN, EfficientNet, CNN-GRU, Fake, Real, Audio Manipulation, Feature Extraction, Deep Learning, Real-Time Detection, Python, TensorFlow, Keras.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
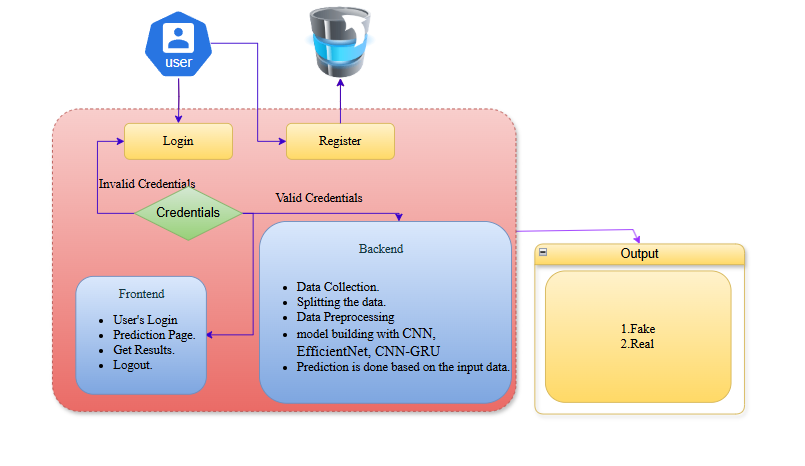
Specifications
SOFTWARE REQUIREMENS
Operating System : Windows 7/8/10
Server side Script : html,css,js
Programming Language : Python
Libraries : Django, Pandas, Torch, Keras, Sklearn,Numpy , Seaborn
IDE/Workbench : VSCode
Server Deployment : Xampp Server
Database : SQLite
HARDWARE REQUIREMENTS
Processor - I3/Intel Processor
RAM - 8GB (min)
Hard Disk - 128 GB
Key Board - Standard Windows Keyboard
Mouse - Two or Three Button Mouse
Monitor - Any




 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.