Design of Radix-8 Unsigned Bit Pair Recoding Algorithm-Based Floating-Point Multiplier for Neural Network Computations
Also Available Domains Communications
Objective
The primary objective of this project is to design a high-performance floating-point multiplier based on the Radix-8 Unsigned Bit Pair Recoding algorithm, specifically optimized for neural network computations. Neural networks require a large number of multiply-accumulate operations, making efficient multipliers crucial for accelerating deep learning tasks. The proposed design aims to reduce the number of partial products generated during multiplication by utilizing Radix-8 recoding, thereby minimizing hardware complexity, latency, and power consumption. By maintaining compliance with the IEEE 754 floating-point standard, the design ensures accuracy and compatibility in real-world applications. This multiplier architecture targets hardware platforms such as FPGAs or ASICs, aiming to improve speed, area efficiency, and energy performance in neural network processors. Performance evaluation will include a detailed analysis of delay, power, and resource utilization compared to traditional Radix-2 and Radix-4 designs, demonstrating its suitability for real-time and energy-constrained AI systems.
Abstract
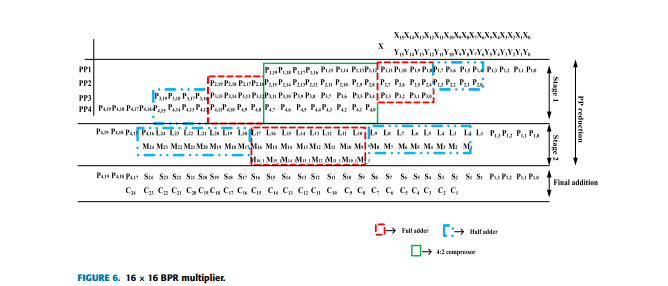
The neural network computations for Artificial Intelligence (AI) applications demand high speed, low power and area-efficient Floating-Point (FP) multiplication. In this work, we propose an efficient unsigned Bit Pair Recoding (BPR) algorithm for area, power, and speed improved FP unsigned mantissa multiplication. The partial product rows are reduced from n to n 4 for n × n binary multiplier using the BPR algorithm with parallel processed partial product reduction. The new algorithm performs partial product row reduction without the 2’s complement, Negative Encoding (NE), and Sign Extension (SE) are required for Booth recoded-based multiplication but these computations are not required for floating point unsigned multiplication. The computational cost of determining a 2’s complementary circuit and neglecting the sign bit extension of each partial product row in the Modified Booth Encoding (MBE) algorithm is effectively eliminated by BPR algorithm. The unsigned mantissa multiplication using partial product array reduction with the BPR technique uses 27.5% less area, 18% less power, and 33.33% improved speed for generating one partial product row than conventional Booth multipliers. The 8 × 8 and 16 × 16 multipliers are used to verify the BPR binary multipliers on TSMC 65nm 1.1 V CMOS standard cell library and the synthesis reports are compared with the conventional and best-reported improved Booth multipliers. Finally, the MAC design uses 16-bit FP arithmetic with an 8×8 mantissa multiplier for the CNN accelerator is developed, and it is validated with suitable error metrics like Mean Relative Error (MRE) to assess the suggested architecture for AI applications.
INDEX TERMS Area efficient multiplier, bit pair recoding (BPR) algorithm, booth encoding algorithm, error analysis, fast multiplication, low power multiplier, multipliers for neural networks, partial product reduction.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
Specifications
Software Requirements:
VIVADO 2018.3
Hardware Requirements:
· Microsoft® Windows XP
· Intel® Pentium® 4 processor or Pentium 4 equivalent with SSE support
· 512 MB RAM
· 100 MB of available disk space
Learning Outcomes
- Basics of Digital Electronics
- VLSI design Flow
- Applications in real time
· VIVADO for design and simulation
· Solution providing for real time problems
· Project Development Skills:
o Problem Analysis Skills
o Problem Solving Skills
o Logical Skills
o Designing Skills
o Testing Skills
o Debugging Skills
o Presentation Skills
o Thesis Writing Skills



 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.