Deep Learning Techniques for Automated Speaker Recognition System
Objective
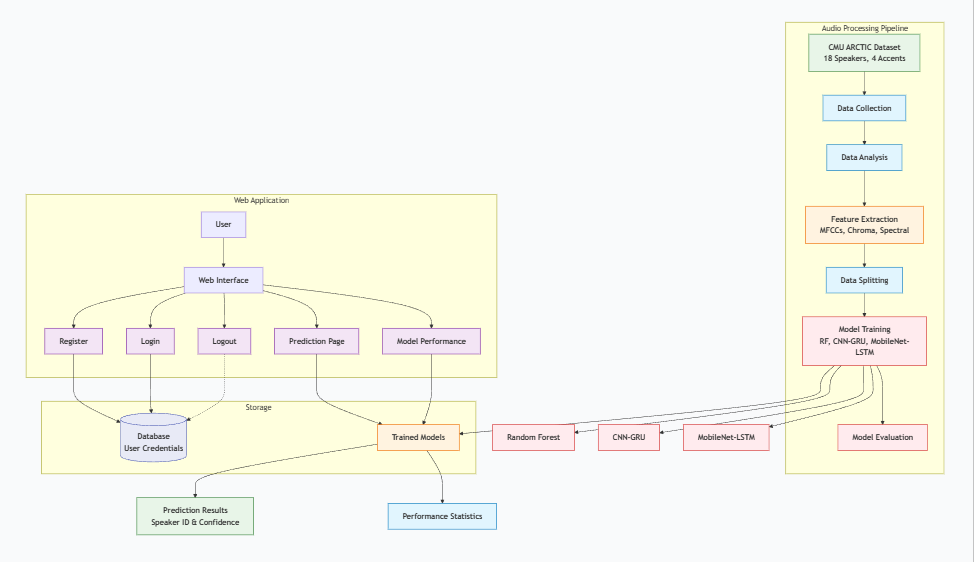
This project presents an advanced automated speaker recognition system using deep learning techniques for precise multi-speaker identification. Built on a subset of the CMU ARCTIC dataset, it includes audio from 18 speakers (13 male, 5 female) with diverse accents: US, Indian, Canadian, and Scottish English. The system employs three models: a Random Forest baseline, a hybrid CNN-GRU architecture for spatial-temporal patterns, and a lightweight MobileNet-LSTM combination for efficient deployment. Training used acoustic features like MFCC, delta coefficients, chroma features, and spectral contrast for speaker-specific traits. A secure web application was developed with user login and accurate speaker prediction from audio files.
Abstract
This project introduces an advanced automated speaker recognition system designed for precise multi-speaker identification using cutting-edge deep learning techniques. The system is built on a curated subset of the CMU ARCTIC dataset, incorporating high-quality audio recordings from 18 diverse speakers (13 male and 5 female) encompassing a range of accents: US English (9 speakers), Indian English (6), Canadian English (2), and Scottish English (1). This diversity ensures robustness across linguistic variations.
Several models were developed and rigorously evaluated: a Random Forest classifier serving as the baseline, a hybrid CNN-GRU architecture for capturing spatial and temporal patterns, and a lightweight MobileNet combined with LSTM for efficient deployment. Training utilized a comprehensive set of acoustic features, including Mel-Frequency Cepstral Coefficients (MFCC), delta and delta-delta coefficients, chroma features, and spectral contrast, to extract discriminative speaker-specific traits.
To facilitate practical usability, a secure web application was implemented with user registration/login mechanisms and real-time speaker prediction functionality upon audio file upload. The system demonstrates high accuracy and reliability, positioning it as a promising solution for biometric authentication, voice-based security systems, and forensic speaker verification applications.
Keywords
Speaker Recognition, Deep Learning, CMU ARCTIC Dataset, MFCC, Delta Coefficients, CNN-GRU, MobileNet-LSTM, Random Forest, Acoustic Features, Chroma, Spectral Contrast, Web Application, Biometric Authentication, Forensic Analysis
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
Specifications
1. SOFTWARE REQUIREMENS
Operating System : Windows 7/8/10
Server-side Script : HTML, CSS, Bootstrap & JS
Programming Language : Python
Libraries : Flask, Pandas, Sklearn, tensorflow,librosa
NumPy, Seaborn, Matplotlib,
IDE/Workbench : VSCode
Technology : Python 3.8+
Server Deployment : Xampp Server
Database : MySQL
2. HARDWARE REQUIREMENTS
Processor - I5/Intel Processor
RAM - 8GB+ (min)
Hard Disk - 128 GB+
Key Board - Standard Windows Keyboard
Mouse - Two or Three Button Mouse
Monitor - Any

Demo Video


Request for Video
 Paper Publishing
Paper PublishingRequest Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.