Deep Learning Approaches for Speech Recognition Systems
Objective
To develop a deep learning-based speech recognition system that can accurately identify and differentiate between multiple speakers using their unique voice patterns. This enhances speaker-specific applications such as authentication, virtual assistants, and security systems.
Abstract
This project aims to develop an efficient speech recognition system using deep learning techniques to identify and differentiate between multiple speakers. Voice recordings from various users, such as User1, User2, and User3, are collected to form a comprehensive dataset for training the model. By leveraging deep neural networks, the system learns distinct vocal characteristics and patterns unique to each individual, enabling accurate speaker recognition. After training, the model is tested to assess its performance in real-time speaker identification scenarios. This deep learning-based approach enhances the accuracy and reliability of speech recognition systems, making it suitable for applications such as voice authentication, personalized virtual assistants, and security verification.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
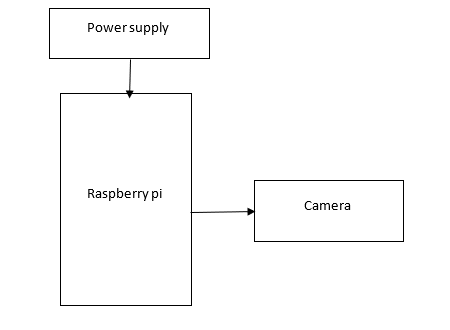
Specifications
Hardware components:
- Raspberry pi
- Camera
- Power supply
Software components:
- Raspbian os
- Python
Learning Outcomes
- Arduino and Raspberry Pi pin diagrams and architectures
- How to install Arduino IDE and Raspberry Pi OS
- Setting up and installation procedures for Arduino and Raspberry Pi
- Introduction to Arduino IDE and Raspberry Pi programming environments such as Thonny and Terminal
- Basic coding in Arduino IDE and Python programming on Raspberry Pi
- Basics of Embedded C language for Arduino and Python for Raspberry Pi
- Basics of IoT platforms using Arduino and Raspberry Pi
- Working of power supply for Arduino and Raspberry Pi systems
- About Project Development Life Cycle
- Planning and requirement gathering including software tools and hardware components for both Arduino and Raspberry Pi
- Schematic preparation
- Code development and debugging for Arduino and Raspberry Pi
- Hardware development and debugging for both platforms
- Development of the project and output testing
- Practical exposure to hardware and software tools for Arduino and Raspberry Pi
- Solution providing for real-time problems
- Working with team or as an individual
- Working on creative ideas involving Arduino and Raspberry Pi
- Project development skills including problem analyzing skills
- Problem solving skills
- Creativity and imaginative skills
- Programming skills in Embedded C for Arduino and Python for Raspberry Pi
- Deployment
- Testing skills
- Debugging skills
- Project presentation skills
- Thesis writing skills



 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.