Crime Type and Occurrence Prediction in Machine Learning Algorithm
Objective
The main objective of Crime Type and Occurrence Prediction in Machine Learning Algorithm is to develop a model that can accurately predict the type of crime and its likelihood of occurrence based on historical crime data, enabling proactive measures and resource allocation for crime prevention and law enforcement. By leveraging machine learning techniques, the aim is to create a reliable system that aids in identifying patterns, trends, and factors contributing to different types of crimes, ultimately improving public safety and crime management strategies.
Abstract
Ensemble learning method is a collaborative decision-making mechanism that implements to aggregate the predictions of learned classifiers in order to produce new instances. Early analysis has shown that the ensemble classifiers are more reliable than any single part classifier, both empirically and logically. While several ensemble methods are presented, it is still not an easy task to find an appropriate configuration for a particular dataset. Several prediction-based theories have been proposed to handle machine learning crime prediction problem. It becomes a challenging problem to identify the dynamic nature of crimes. Crime prediction is an attempt to reduce crime rate and deter criminal activities. This work proposes an efficient authentic method called assemble-stacking based crime prediction method (SBCPM) based on algorithms for identifying the appropriate predictions of crime by implementing learning-based methods applied to achieve domain-specific configurations compared with another machine learning model. The result implies that a model of a performer does not generally work well. In certain cases, the ensemble model outperforms the others with the highest coefficient of correlation, which has the lowest average and absolute errors. The proposed method achieved classification accuracy on the testing data. The model is found to produce more predictive effect than the previous researches taken as baselines, focusing solely on crime dataset based on violence.
Keywords: Decision tree, Random Forest, Logistic Regression and Machine learning techniques
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
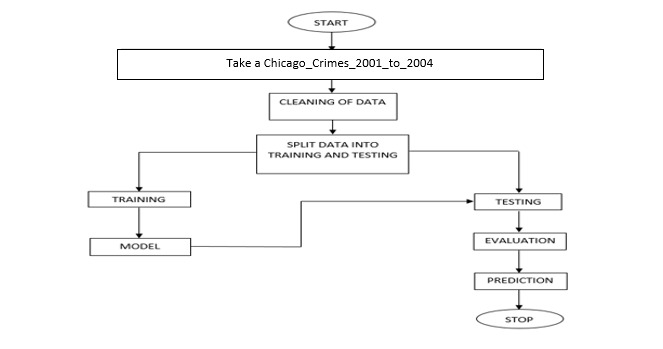
Block Diagram
Specifications
SOFTWARE FRONT END REQUIREMENTS
H/W CONFIGURATION:
Processor - I3/Intel Processor
Hard Disk -160 GB
RAM - 8 GB
S/W CONFIGURATION:
Operating System : Windows 7/8/10 .
Server side Script : HTML, CSS & JS.
IDE : Pycharm.
Libraries Used : Numpy, IO, OS, Django, keras.




 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.