Area-Efficient Modular Multiplication on FPGA
Objective
Modular multiplication (MM) involves multiplica tion and modular reduction. In this brief, we explore an area-efficient modular reduction for MM on FPGA. We analyze and compare the equivalent LUT6 (ELUT6) cost when imple menting modular reduction using different memory strategies (BRAM/LUT6/LUT5), and adopt LUT5 (lowest ELUT6 cost) as the memory for this design
Abstract
Modular multiplication (MM) involves multiplica tion and modular reduction. In this brief, we explore an area-efficient modular reduction for MM on FPGA. We analyze and compare the equivalent LUT6 (ELUT6) cost when imple menting modular reduction using different memory strategies (BRAM/LUT6/LUT5), and adopt LUT5 (lowest ELUT6 cost) as the memory for this design. Then we propose an area-efficient compression strategy with a new (1,5;3) Generalized Parallel Counter (GPC), which reduces the LUT6 cost of compression operation in modular reduction compared to previous methods. Finally, we adopt the 4-term Karatsuba algorithm to reduce the area of multiplication, and explore the balance of hardware delay in MM. The proposed MM is implemented on the Xilinx Virtex-7 platform. Compared to the previous state-of-art pipeline design, the area of proposed MM is only 41.7%/47.6%/47.6%/50.0% of them when word-size w=32/64/128/256.
Index Terms—Cryptography, modular multiplication (MM), pipeline design, generalized parallel counter (GPC), FPGANOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
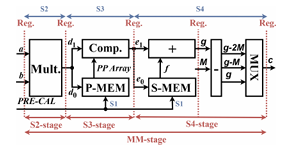
Specifications
Specifications:
Software Requirements:
· VIVADO 2018.3
Hardware Requirements:
· Microsoft® Windows XP
· Intel® Pentium® 4 processor or Pentium 4 equivalent with SSE support
· 512 MB RAM
· 100 MB of available disk space
Learning Outcomes
- Understanding modular multiplication architecture on FPGA
- Knowledge of memory optimization (LUT5 vs LUT6 vs BRAM)
- Insight into Generalized Parallel Counters (GPCs)
- Learning Karatsuba multiplication (advanced version)
- Ability to analyze area-delay trade-offs in hardware design
- Understanding pipeline optimization techniques in FPGA.



 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.