Anomaly Detection and Root Cause Analysis in Cloud-Native Environments Using Large Language Models and Bayesian Networks
Objective
The objective of this study is to develop an automated anomaly detection framework for microservices architectures using Large Language Models (LLMs). The framework aims to accurately identify anomalies in distributed systems, provide root cause analysis through dynamic Bayesian networks, and offer interactive insights via a ChatBot, ultimately enhancing system reliability and reducing the manual effort required for incident analysis.
Abstract
Cloud computing technologies offer significant advantages in scalability and performance, enabling rapid deployment of applications. The adoption of microservices-oriented architectures has introduced an ecosystem characterized by an increased number of applications, frameworks, abstraction layers, orchestrators, and hypervisors, all operating within distributed systems. This complexity results in the generation of vast quantities of logs from diverse sources, making the analysis of these events an inherently challenging task, particularly in the absence of automation. To address this issue, Machine Learning techniques leveraging Large Language Models (LLMs) offer a promising approach for dynamically identifying patterns within these events. In this study, we propose a novel anomaly detection framework utilizing a microservices architecture deployed on Kubernetes and Istio, enhanced by an LLM model. The model was trained on various error scenarios, with Chaos Mesh employed as an error injection tool to simulate faults of different natures, and Locust used as a load generator to create workload stress conditions. After an anomaly is detected by the LLM model, we employ a dynamic Bayesian network to provide probabilistic inferences about the incident, proving the relationships between components and assessing the degree of impact among them. Additionally, a ChatBot powered by the same LLM model allows users to interact with the AI, ask questions about the detected incident, and gain deeper insights. The experimental results demonstrated the model’s effectiveness, reliably identifying all error events across various test scenarios. While it successfully avoided missing any anomalies, it did produce some false positives, which remain within acceptable limits.
Keywords-Cloud Computing, Anomaly Detection, Microservices, Kubernetes, Bayesian Networks, Large Language Models, Root Cause Analysis.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
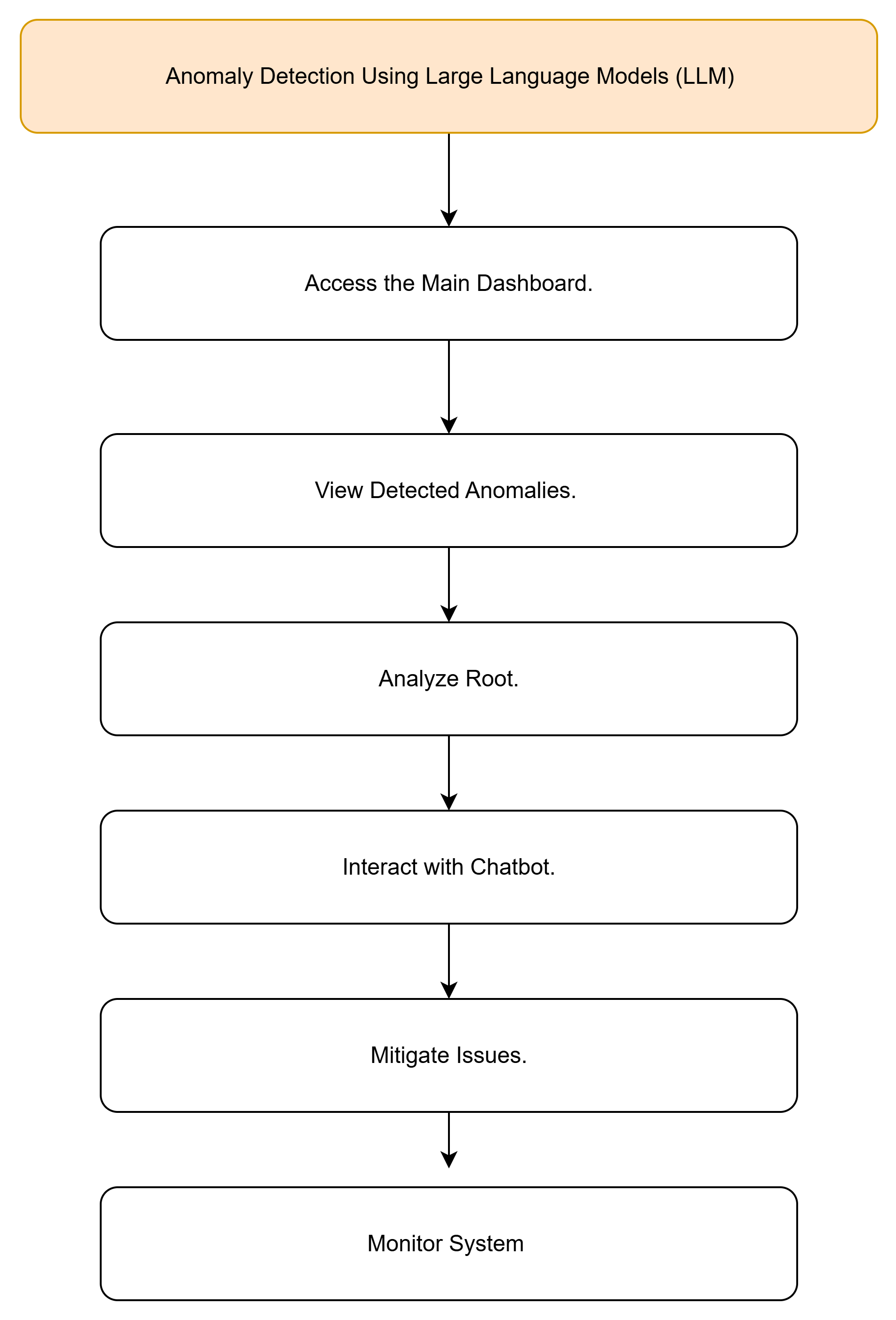
Block Diagram
Specifications
Software Requirements:
- Operating System:
- Windows 7/8/10 (for local development via Minikube or WSL2)
- Backend:
- Python (Flask/FastAPI for API development)
- Machine Learning Libraries/Frameworks (for training and anomaly detection)
- IDE/Workbench:
- VS Code (Integrated Development Environment)
- Docker (for containerization of applications)
Cloud-Native Stack:
- Kubernetes:
- For container orchestration to manage and scale applications.
- Istio:
- Service mesh for observability, traffic management, and security between microservices.
- Docker:
- For containerizing the microservices and other components of the system.
- Chaos Mesh:
- Tool for fault injection to simulate real-world errors and stress test the system.
- Locust:
- Load generation tool for simulating high traffic and stress conditions on the system.
Hardware Requirements:
- Processor:
- Intel Core i5 or equivalent (for local development)
- Hard Disk:
- 200GB SSD (for faster storage and access to large datasets and containers)
- GPU:
- NVIDIA A100 (recommended for ML workloads, especially if training large models)
- Cluster:
- At least 3 Kubernetes worker nodes (8 vCPUs, 16GB RAM each) for distributed processing and orchestration.
- Peripheral Devices:
- Standard Windows keyboard and two or three-button mouse for user interaction.
- Monitor:
- SVGA (standard video graphics array resolution)
- RAM:
- 32GB of RAM for running multiple services and containers smoothly in a Kubernetes cluster.




Related Projects
 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.