An Experimental Study with Imbalanced Classification Approaches for Credit Card Fraud Detection
Abstract
This paper process the detection and prevention of fraudulent activities are critically important to financial institutions. Credit card fraud is a criminal offense. Fraud detection and prevention are costly, time-consuming, and labor-intensive tasks.
Imbalance classification consists of having a small number of observations of the minority class compared with the majority in the data set. We explored these solutions along with the machine learning algorithms used for fraud detection. We identified their weaknesses and summarized the results that we obtained using a credit card fraud labeled dataset.
According to this paper, imbalanced classification approaches are ineffective, especially when the data are highly imbalanced and reveals that the existing approaches result in a large number of false alarms, which are costly to financial institutions.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
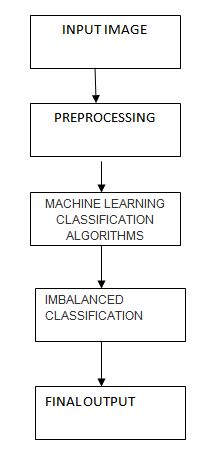
Block Diagram
Specifications

Contact Us
- info@takeoffprojects.com
- +91 9030333433, +91 9393939065



 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.