A CNN light vision transformer framework with channel - spatial attention for glaucoma detection with explainable AL
Objective
Deep learning systems in automating detection can classify fundus images as either normal or glaucomatous with high accuracy for early diagnosis and thereby gain diagnostic thrust into the very domain of preventing visual akinesia. ? Implementation of Various Deep Learning Models: Different modalities involved include CNN with and without channel - spatial attention, MobileNet, vision transformers (ViT) and ResNet/DenseNet for feature extraction and analysis where input to the model manipulated with optimized feature images yields better discrimination. ? Interpretability Improvement through XAI: Grad-CAM will generate heat maps indicating regions in the fundus images where tissue will assume importance with regard to model prediction, thereby rendering the prediction clinically viable. ? Scalability and Efficiency: Its lightened and optimized for mobile devices for glaucoma screen by mobile networks from the most remote and least served areas. ? Absolute Model Performance Evaluation and Comparison: The models will be evaluated for their performance on the basis of specific measurable criterions: accuracy, precision, recall, F1-score, and AUC-ROC. Then, pairwise comparison of the models with each other helps in the analysis of the best architecture for glaucoma detection. ? Support Clinical Integration: Integrate trusted, interpretable outputs into the system to support ophthalmologists with their day-to-day decision-making, enriching the diagnostic workflow and improving access through telemedicine. ? Advance Insight into Future Studies of Glaucoma Detection: That introduces AI field diagnostics from complex architectures implementation and explainable AI toward future studies of glaucoma detection.
Abstract
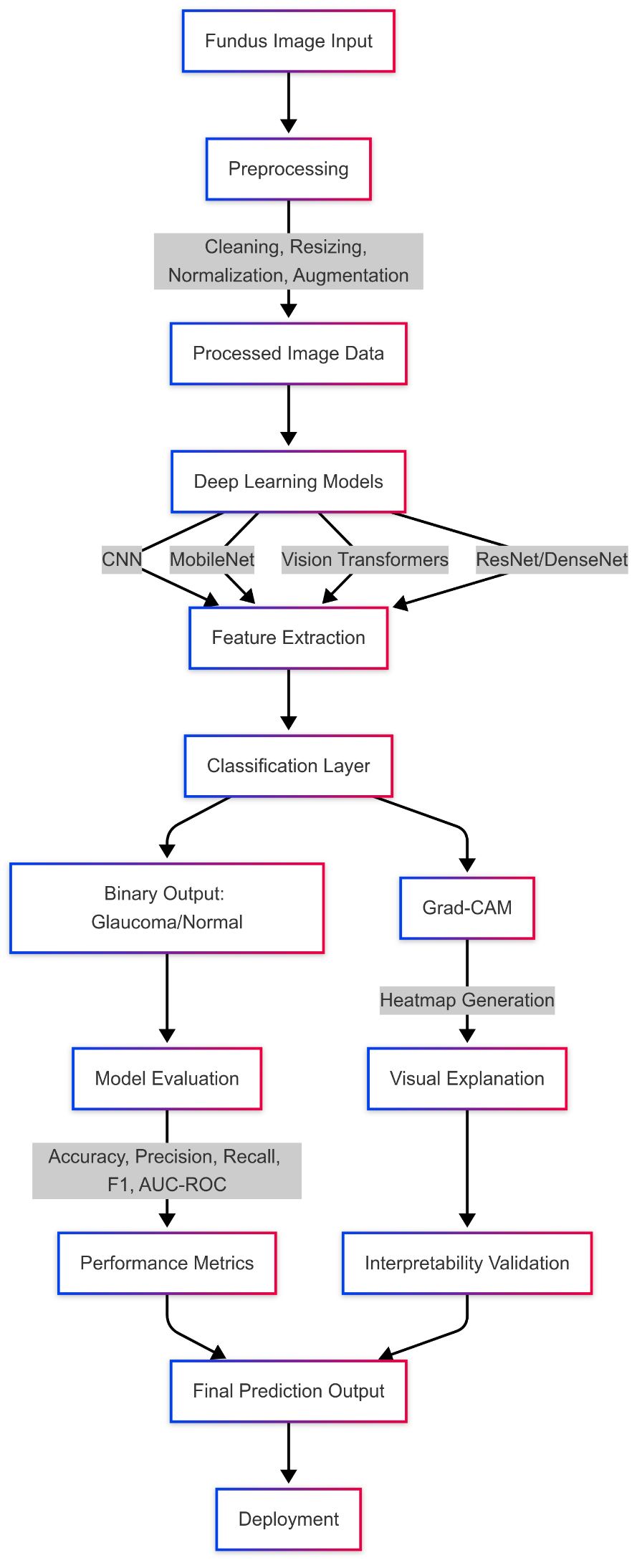
With an observed increase in the incidence of glaucoma, which is one of the leading causes of irreversible blindness, it is essential to have an early and accurate diagnostic apparatus. The present study describes a deep-learning model-based automated detection system for identifying glaucoma based on fundus image data obtained from the Kaggle database Glaucoma Classification Datasets that involve two categories-glaucoma and normal. The proposed system utilizes an arsenal of state-of-the-art deep learning architectures for the robust and accurate classification of glaucoma, from convolutional neural networks (CNN) with and without channel - spatial attention and MobileNet to Vision Transformers (ViT) and ResNet/DenseNet. Channel Attention highlights important feature channels using pooling and fully connected layers. Spatial Attention focuses on relevant spatial regions by using pooled features across channels. Both are used in CBAM to improve feature representation and network performance. Further, Explainable Artificial Intelligence (XAI) techniques-GRAD-CAM-have been integrated to improve the interpretability of the model's predictions by providing visual explanations for the rationale behind decision-making.
Methodologically, after preprocessing the fundus images to ensure a level playing ground in terms of standard input with regards to size and color distribution, the selected deep learning models were exposed to training and testing. CNNs were suitable for extracting huge hierarchical features from images like those subtle patterns that are expressed in the presence of glaucoma. MobileNet is utilized for its lightweight architecture, in allowing efficient deployment on resource-limited devices that form the basis for large-scale screening in clinical settings. Vision Transformers, with their attention-like mechanisms, were evaluated for their capabilities to capture long-range dependencies present in images and hence possibly improve the detection of complex features related to glaucoma. ResNet and DenseNet employ deep architectures with skip connections to resolve issues of vanishing gradient and promote feature reuse, thereby establishing a solid classification performance.
Grad-CAM has been integrated into the pipeline to produce heatmaps showing regions in the fundus images that most influenced the model's predictions, thus addressing the black-box aspect of deep learning models. This enables both validation of the model's attention to clinically relevant areas (such as the optic disc and retinal nerve fiber layer) and the enhancement of medical professionals' trust through the provision of interpretable output. Thus, the system takes as input a fundus image and predicts whether it falls under Glaucoma or a Normal category with an output of binary classification.
For thorough evaluation of the performance of the model, the datasets are trained, validated, and tested. Evaluating the effectiveness of the model is through accuracy, precision, recall, F1-score, and area under the receiver operating characteristic curve (AUC-ROC). Upon comparative model analysis, a trade-off in terms of their strengths and weaknesses is laid forth, with the assumption being that Vision Transformers and ResNet/DenseNet would perform better than simpler architectures since they wield advanced feature extraction capabilities. MobileNet, despite being more prone to lower accuracy, stands out because of its effectiveness towards deployment.
The study mostly aims for the enhancement of ophthalmic diagnostics with a reliable, interpretable, and scalable solution for glaucoma detection. The XAI integration ensures that the system is not only accurate but also clinically trustworthy that enables the real-world adoption of the model. Future work will include the expansion of datasets, the integration of multi-modal data (such as optical coherence tomography), and optimization of models for real-time applications, thereby aiding the fight against vision loss from glaucoma.
Keywords: Glaucoma detection, deep learning, CNN, channel - spatial attention, MobileNet, Vision Transformers, ResNet, DenseNet, XAI, Grad-CAM, fundus images.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
Specifications
H/W CONFIGURATION:
Processor - I3/Intel Processor
Hard Disk - 160GB
Key Board - Standard Windows Keyboard
Mouse - Two or Three Button Mouse
Monitor - SVGA
RAM - 8GB
S/W CONFIGURATION:
• Operating System : Windows 7/8/10
• Server side Script : HTML, CSS, Bootstrap & JS
• Programming Language : Python
• Libraries : Flask, Pandas, MySQL. Connector, Scikit-Learn
• IDE/Workbench : VS Code
• Technology : Python 3.8+
• Server Deployment : Xampp Server




 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.