Voice Assisted Text Reading System For Visually Impaired Persons Using Arduino
Abstract
In the survey American Foundation for Blind 2014, is observed that there are 6.8 trillion people are visually impaired and they still find difficult to roll their day today life it is important to take necessary measure with the emerging technologies to help them to live the current world irrespective of their impairments. In the motive of supporting the visually impaired, a method is proposed to develop a self-assisted text to speech module in order to make them read and understand the text in an easier way. It is not only applicable for the visually impaired but also to any normal human beings who are willing to read the text as a speech as quickly as possible. A finger mounted camera is used to capture the text image from the printed text and the captured image is analyzed using optical character recognition (OCR). A predefined dataset is loaded in order to match the observed text with the captured image. Once it is matched the text is synthesized for producing speech output. The main advantage of proposed method is that, it reduces the dataset memory required for the comparison since only character recognition is being done.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
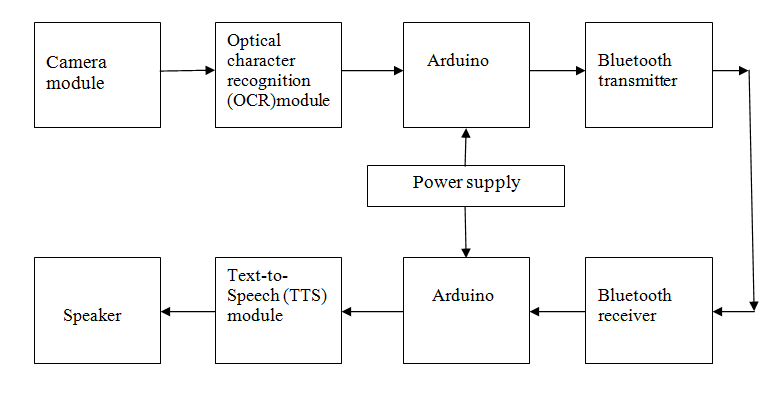
Specifications
Hardware Requirements:
- Arduino.
- Camera module.
- Optical character Recognition(OCR ) module.
- Bluetooth Transmitter.
- Bluetooth Receiver.
- Text -to -speech module.
- Speaker.
- Power supply
- 12v 1a adapter
Software Requirements:
- Arduino IDE
- Embedded C
Learning Outcomes
- Micro controller pin diagram and architecture
- How to install Arduino IDE software
- Setting up and installation procedure for Arduino
- Introduction to Arduino IDE
- Basic coding in Arduino IDE
- About Project Development Life Cycle:
- Planning and Requirement Gathering ((Hardware components, etc.,)
- Hardware development and debugging
- Development of the Project and Output testing
- Practical exposure to:
- Hardware tools.
- Solution providing for real time problems.
- Working with team/ individual.
- Work on Creative ideas.
- Project development Skills
- Problem analyzing skills
- Problem solving skills
- Creativity and imaginary skills
- Testing skills
- presentation skills
- Thesis writing skills



 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.