Personal Loan Fraud Detection Based on Hybrid Supervised and Unsupervised Learning
Objective
The objective of this project is to predict personal fraud load detections. Our model will help to create predictions which reduce the burden to the people who are continuously working on predictions.
Abstract
In recent years, we have been witnessing a dramatic increase on the personal loan for consumption, due to the rapid development of e-services, including e-commerce, e-finance and mobile payments. Resulting from the lack of effective grid verification and supervision, it inevitably leads to largescale losses caused by credit loan fraud. Considering the difficulty of manual inspection and verification on the large amount of credit card transactions, machine learning methods are commonly used to detect fraudulent transactions automatically. This article has applied the Extreme Gradient Boosting (XGBoost) model for data mining and analysis, which is inspired by its brilliant reputation in various data mining contests. With people’s growing concern about privacy protection, how can we apply data mining techniques while taking consideration into privacy terms is one problem.
Additionally, according to current loan fraud detection studies, some features are considered to contain little information or a bit of redundancy, whereas others hold the critical information which makes things harder when feature engineering. In order to filter useless information and preserve the useful information without knowing the meaning of our data, this paper combines Kernel Principal Component Analysis (Kernel PCA) together with XGBoost algorithm and proposes a new hybrid unsupervised and supervised learning model, KPXGBoost. It turns out that P-XGBoost outperforms XGBoost in fraud detection, which provides a new perspective to detecting the fraud behaviour while protecting clients’ privacy.
Key Words: Financial transactions, Fraud, Patterns etc.,
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
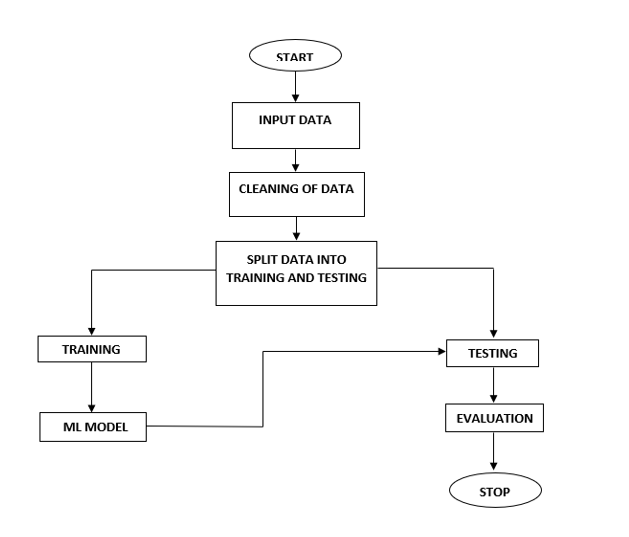
Specifications
- Processor: I3/Intel
- Processor RAM: 4GB (min)
- Hard Disk: 128 GB
- Key Board: Standard Windows Keyboard
- Mouse: Two or Three Button Mouse
- Monitor: Any
- Operating System: Windows 7+
- Server-side Script: Python 3.6+
- IDE: Jupyter Notebook
- Libraries Used: Pandas, Numpy
Learning Outcomes
- About Python.
- About Pandas.
- About Numpy.
- About Machine Learning.
- About Artificial Intelligent.
- About how to use the libraries.
- Virtualization.
- About model choosing.
- Project Development Skills:
- Problem analyzing skills.
- Problem solving skills.
- Creativity and imaginary skills.
- Programming skills.
- Deployment.
- Testing skills.
- Debugging skills.
- Project presentation skills.



 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.
