Novel XGBoost Tuned Machine Learning Model for Software Bug Prediction
Objective
In this project, we verify the effectiveness of XGBoost Algorithm in detecting bugs in software, and compared with the other traditional machine learning algorithms like logistic regression, decision trees, random forest and AdaBoost.
Abstract
Software bug prediction becomes the vital activity during software development and maintenance. Defect prediction at early stages of software development life cycle is a crucial activity of quality assurance process and has been broadly studied in the last two decades.
The early prediction of defective modules in developing software can help the development team to utilize the available resources efficiently and effectively to deliver high quality software product in limited time. Machine learning approach is an effective way to identify the defective modules, which works by extracting the hidden patterns among software attributes.
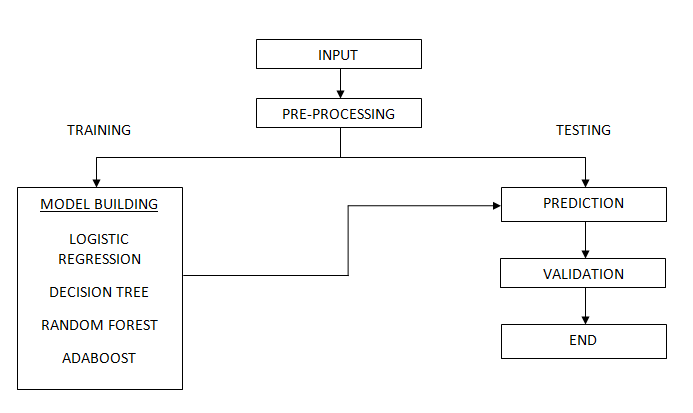
In this project , several machine learning classification techniques are used to predict the software defects in NASA datasets JM1, CM1, KC2 and PC3. New model was proposed based on tuning the existing XGBoost model by changing its parameter namely n_estimator, learning rate, max depth, and subsample. The results achieved were compared with state-of the art models and our model outperformed them for all datasets.
Keywords: Machine Learning, Dataset, Supervised Learning, Random Forest, XgBoost, Ada Boost, Decision Tree.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
Specifications
HARDWARE SPECIFICATIONS:
- Processor: I3/Intel
- Processor RAM: 4GB (min)
- Hard Disk: 128 GB
- Key Board: Standard Windows Keyboard
- Mouse: Two or Three Button Mouse
- Monitor: Any
SOFTWARE SPECIFICATIONS:
- Operating System: Windows 7+
- Server-side Script: Python 3.6+
- IDE: PyCharm
- Libraries Used: Pandas, NumPy, sklearn, Flask, NLTK, TensorFlow.
- Data set: JM1, CM1, KC2 and PC3 Data set.
Learning Outcomes
- Uses of Unsupervised Learning.
- Importance of classification.
- Scope of XGBoost.
- Use of Boosting techniques.
- Importance of Jupyter Notebook.
- How ensemble models works.
- How boosting and bagging benefits simple ensemble techniques.
- How gradient boosting enhances a models performance.
- Process of debugging a code.
- The problem with imbalanced dataset.
- Benefits of SMOTE technique.
- Input and Output modules
- How test the project based on user inputs and observe the output
- Project Development Skills:
- Problem analyzing skills.
- Problem solving skills.
- Creativity and imaginary skills.
- Programming skills.
- Deployment.
- Testing skills.
- Debugging skills.
- Project presentation skills.
- Thesis writing skills.



 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.