Effect of Data Parameters and Seeding on k-Means and k-Medoids
Objective
The main objective of this project is to increase the cluster overlapping for seed dataset; it can generate better overlapping to cluster results. We are implementing the employ the state-of-art D2-weighting technique of k-means++, a variant of k-means++.
Abstract
In clustering, a group of different data objects is classified as similar objects. A group is a data cluster. In cluster analysis, the data sets are divided into different groups, which depend on the similarity of the data.
The k-means and k-medoids are the two most popular clustering methods. Here we report an empirical study of the relative (de) merits of these two methods. We compared their performances in different data situations. We also assess the effect of replacing random selection of initial cluster centers with a systematic approach.
Keywords: Data Mining, Clustering Algorithm, Dataset Classification, K-Means, K-Medoids.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
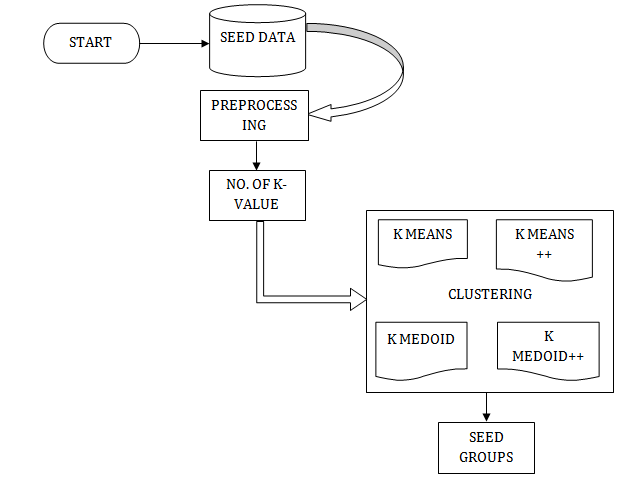
Block Diagram
Specifications
HARDWARE SYSTEM CONFIGURATION:
- Processor- I3/Intel Processor
- Ram- 4GB (min)
- Hard Disk- 160GB
SOFTWARE SYSTEM CONFIGURATION:
- Operating System: Windows 7/8/10
- Application Server: Tomcat 9.0
- Front End: HTML, JSP
- Scripts: JavaScript.
- Server side Script: Java Server Pages.
- Database: My SQL 6.0
- Database Connectivity: JDBC.
Learning Outcomes
- Scope of Real Time Application Scenarios.
- How Internet Works.
- What is a search engine and how browser can work.
- What is Tomcat server and how they can work.
- What types of technology versions are used?
- Use of HTML and CSS on UI Designs.
- Data Base Connections.
- Data Parsing Front-End to Back-End.
- Need of Eclipse-IDE to develop a web application.
- Working Procedure.
- Testing Techniques.
- Error Correction mechanisms.
- How to run and deploy the applications.
- Introduction to basic technologies uses.
- Input and Output modules.
- What Data mining?
- What is clustering?
- What is data base and Dataset?
- Difference between clustering and classification.
- What is k-means clustering? How to solve it.
- What is k-means++ clustering? How we solve it.
- What is k-medoid clustering? How to solve it.
- What is k- medoid++ clustering? How to solve it.
- What is Euclidean distance? How to calculate this.
- Project Development Skills:
- Problem analyzing skills.
- Problem solving skills.
- Creativity and imaginary skills.
- Programming skills.
- Deployment.
- Testing skills.
- Debugging skills.
- Project presentation skills.
- Thesis writing skills.
Demo Video


Request for Video
 Paper Publishing
Paper PublishingRequest Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.
