Cross-domain Sentiment Encoding Through Stochastic Word Embedding
Abstract
Cross-domain Sentiment Encoding through Stochastic Word Embedding
Abstract:
Sentiment analysis is an important topic concerning identification of feelings, attitudes, emotions and opinions from text. A critical challenge for automating such analysis is the high manual annotation cost when conducting large-scale learning. However, the cross-domain technique is a key solution for this. It reuses annotated reviews across domains and its success principally relies on the effort that has been invested to improve the cross-domain representation learning by designing increasingly more complex and elaborate model inputs and architectures. We support that it is not necessary to focus on design complexity as this inevitably consumes more time for model training. Instead, we propose to explore through a simple mapping the word polarity and occurrence information and encode such information more accurately whilst aiming at lower computational costs. The proposed approach is unique and takes advantage of the stochastic embedding technique to tackle cross-domain sentiment alignment. Its effectiveness is benchmarked with over ten data tasks constructed from two review corpora, and is compared against ten classical and state-of-the-art methods.
NOTE: Without the concern of our team, please don't submit to the college. This Abstract varies based on student requirements.
Block Diagram
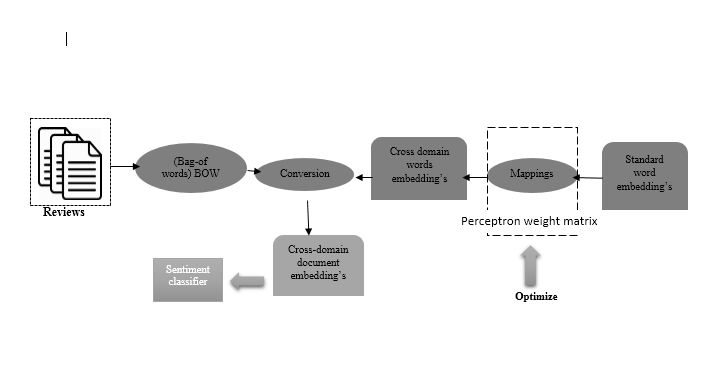
Specifications




Related Projects
 Paper Publishing
Paper Publishing

Request Call Back
Would you like to receive a free callback now?
Choose the best time for callback:
Leave your message and we will contact you as soon as possible

6-2-85/B, Old Maternity Hospital Road, Thyagaraja Nagar, Tirupati, Andhra Pradesh – 517501
+91 9030333433
+91 9393939065
0877-2261612

Disclaimer - Takeoff Edu Group Projects are not associated or affiliated with IEEE in any way. The IEEE Projects mentioned here are mentioned in the context of student projects, whose ideas are derived from IEEE publications, not projects of or by IEEE.